“ 别让错误,以更漂亮的形式出现。 ”
去年 3 月,课代表曾写过一篇关于 可视化打假 ?的新书推荐。相信大家再看到可视化时,会带着更审慎的眼光。
在此基础上,我们还可以通过提升数据敏感性来加强辨别可视化的能力。今天课代表要分享的是蒂姆 • 哈福德(Tim Harford)的《拼凑真相》(How to Make the World Add Up)。作者在书中提出了十个认清纷繁世界的数据法则,我们将与大家分享其中四个适用于解读可视化的法则。
老李在文末给大家留了“亿”点小福利,让我们开始今天的分享吧。

小心可视化视差
当我们使用可视化突出对比时,呈现方式的差异会给人带来完全不同的观感和解读。
彭博社在报道碳排放“贫富差距”时,使用三维柱状图来表现不同国家的碳排放差异。为了突出对比,左右两张可视化选择了不同的数据作为观察视角。

左图中,柱形高度代表一个国家的碳排放总量。右图中,柱形高度代表国家内最富有1%人口与最贫困50%人口间的碳排放差距。彭博社在报道中用对比强烈的可视化说明:除了比较国与国之间的碳排放差异,更应该关注国家内部的碳排放贫富差距。
数据视角对比显著,但可视化视角却不够准确。主要原因是倾斜的三维柱形受透视关系的影响,会在视觉上放大差值较大的数据、缩小差值较小的数据。在左侧的图表中,你很难感受到非洲各国的碳排放差异,但一眼就能看到中美两国的碳排放量。
另一种常见的可视化视角局限是以偏概全。在《拼凑真相》中, 作者建议我们尝试结合“蠕虫”和“鸟瞰”视角来思考问题。 “鸟瞰”像广角,将全景一览无余;“蠕虫”像变焦,将细节尽收眼底。两者相结合,能够更好地看清可视化的全貌。
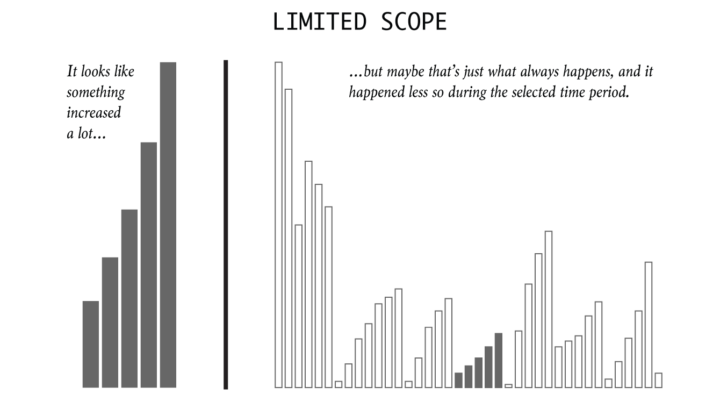
比如这张表达连续变化的柱形图。如果只看左侧的话,你会明显感觉到“一柱更比一柱高”的增长趋势。如果把它们塞到右侧的图表中,它就显得不那么“突出”。一方面是因为有其他柱子拉高了极值,增长趋势被“压扁”了;另一方面是线性的增长规律被打破了,右侧的图表更“参差不齐”。
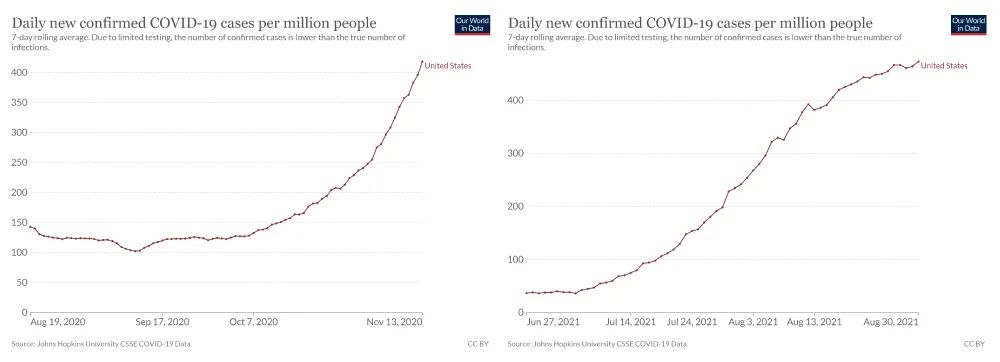
现在不妨让我们来思考这样一个问题:上面这两张图表,哪张更能体现美国新冠新增感染人数的增长趋势?从时间跨度来看,第一张图涵盖的时间更长,似乎更有说服力;从取值范围来看,第二张图似乎更合理。让我们先保留各自的意见,来看下面这张图:
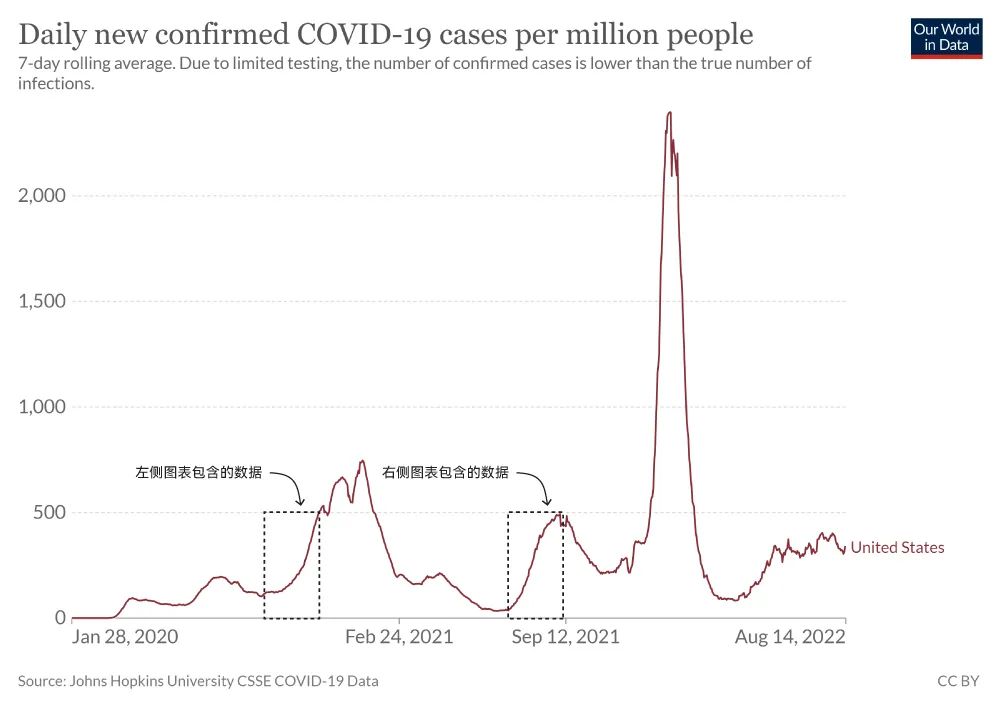
可以明显的看到,上述两张图表在更完整的时间序列中,都不是增长趋势最有特征的。如果你没有看到数据的全貌,很难想象美国在去年 11 月底还有一波更严重的疫情。因此,当你只看到可视化的局部时,你的选择和结论很可能存在偏差,你能回答的问题也非常有限。
这种偏差甚至可能会因为个人经验而被放大,因为你可能会下意识地去相信和认知更接近的“真相”。在《拼凑真相》中,作者提到:
大量吸烟会使患肺癌的风险增加 16 倍,但许多人却因为自己的某个经历对这一发现产生怀疑。譬如你会说你奶奶一辈子吸烟,都活到 90 岁了还身体倍儿棒,而你隔壁的叔叔,一辈子不抽烟,最后却是死于肺癌。
虽然肺癌发病率风险增加 16 倍不是个小数字,但肺癌病例本身很少,所以我们把自身经历的特殊性当成普遍性了。
如果只看数据,我们可能只看到了冰山一角。有些现象和趋势,即便获得真实的数据,也不一定能够通过一张可视化就完全分析出背后的原因。因此作者的建议是:
所以在看完数据表格之余,我们也可以抬起头来,带着好奇心去看、去听、去摸,去感受真实的世界。

不乱于心,不困于情
可视化图表有时还起到了“以形表意”的作用。在《拼凑真相》中,作者这样形容可视化:
图形更能唤起我们的想象力和情绪。
这样的说法并不完全是褒义的。如果精妙的可视化设计能够赋予读者先入为主的印象,诱导读者在尚未消化信息前就产生态度;那么可视化图表的“唤起”功能,就有可能成为一种预设的陷阱。
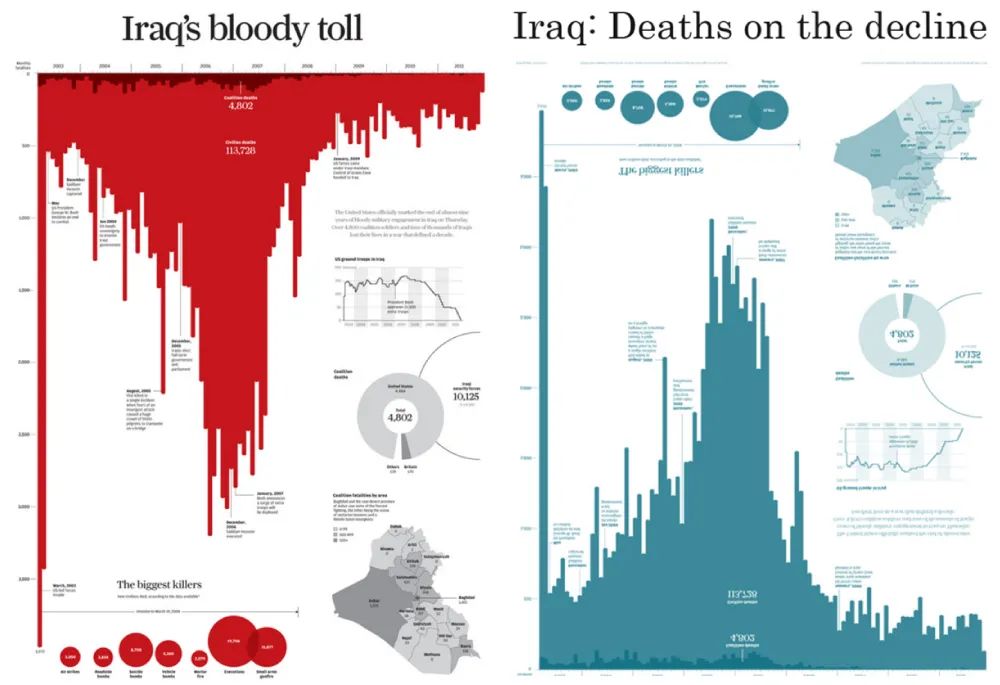
这两张图表使用的数据基本相同,但带给读者的视觉感受和情绪却完全不同。左侧是西蒙·斯卡尔 2011 年发表于华南早报的《泣血鸣告:伊拉克的死亡人数》。设计师利用标题、色彩和柱状图的朝向,将死亡人数表现得如同滴落的鲜血,传递出一种悲愤的批判。
而右侧这张由安迪·科特格雷夫设计的图表,只是调整了配色和柱状图的朝向,就给人带来完全不同的情绪和主题:冷色调的蓝好像战争在“降温”,死亡人数减少的趋势甚至传递了一丝希望。这也正契合了图表的标题——《曙光在望:伊拉克死亡人数在下降》。
因此当我们欣赏可视化精妙的设计之余, 应当警惕埋藏在美感背后的煽动和情绪陷阱。 在《拼凑真相》,作者给出这样的建议:
警惕视觉触发的感受对正确解读信息的影响,不可只关注图形,还应当自省是否理解图中的数据和轴线的含义。

看清数据的自我介绍
在看到统计数据时, 我们往往会基于经验和常识去解读结论。 这种判断方式会将我们引向错误的方向,或者得到一个片面的答案。避免这种情况发生的方法也很简单,那就是明确数据是如何定义的。
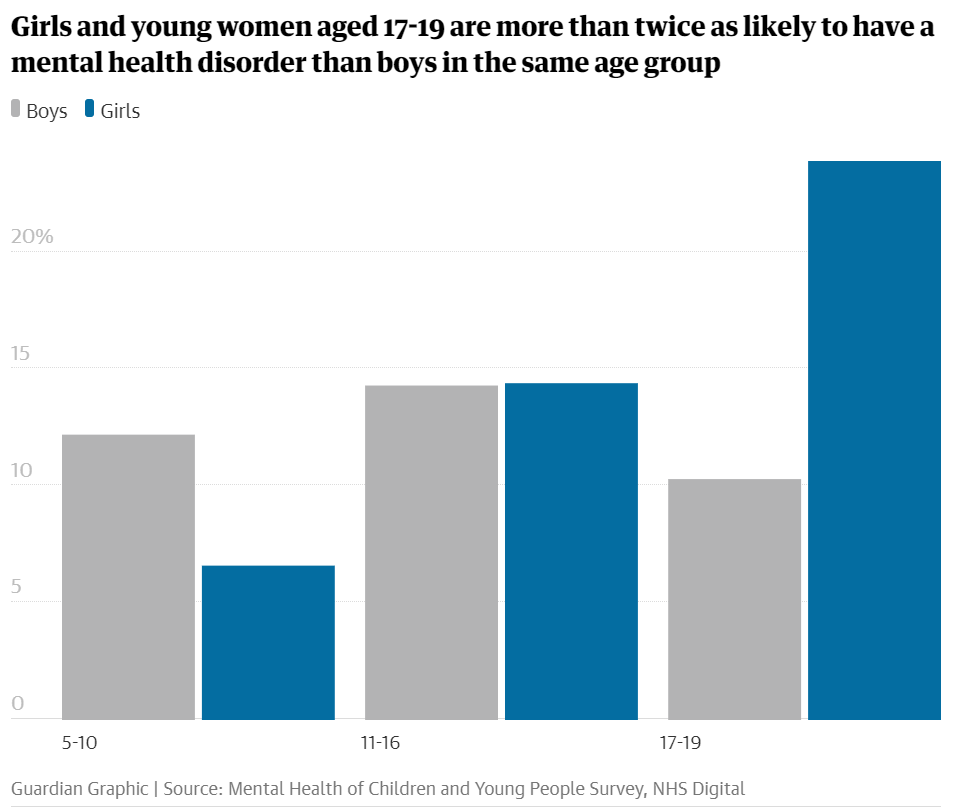
比如这张英国《卫报》在报道女性自杀倾向时用的图表,可以看到 17 至 19 岁女性患有精神障碍的概率几乎是同龄女性的两倍。看完图表后,我们会自然地揣测是不是社交媒体、容貌焦虑、性暴力等因素让这个年龄段的女性更容易产生心理健康问题。事实上,这篇报道的后续展开也是如此进行的。
但研究诸多原因后我们会发现,对于精神障碍的定义,文中并没有给出确切的解释。这篇报道还将自残和自杀放在一个话语体系下讨论,显然也不够严谨。
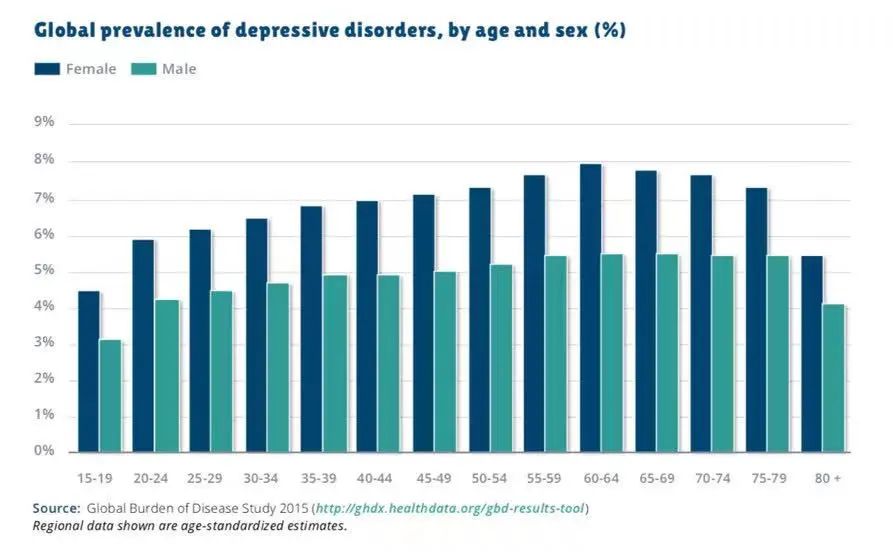
相比较而言,世界卫生组织这张关于“不同年龄、性别患抑郁症比例”的图表则更聚焦一些。这种差异表明,不同的数据源往往会造成结论的偏差。
但我们依旧可以对这个数据结论进行追问:“世界卫生组织是如何定义抑郁症的?”不要因为发布者的权威性而忽略对数据定义的核查。不明确的数据定义,将导致错误或者狭隘的认知。在《拼凑真相》中,作者建议:
此刻,我希望你已培养了习惯,能追问有关当局对“自杀”是怎么定义的。......要学会问问题:问问统计对象是什么,统计数据背后有什么故事。

客观数据 or 主观人为
数据往往代表了理性和客观,这种观点一部分人的“刻板印象”。他们较少对数据产生质疑,往往会忽视数据本身的偏误。在《拼凑真相》中,作者这样解释数据存在误差的原因:
现实中,任何统计事项还是由人来决定的:收集什么信息、不收集什么信息、统计什么、不统计什么、统计对象是谁,这些都有人为的观点、成见和疏漏掺杂其中。
简单来说, 人们的认知局限和主观偏见,会对收集的数据产生影响。 当收集的数据不够全面、缺乏代表性时,便会导致对真实情况的预测出现问题。
1936 年美国《文学文摘》对大选形势的错误预估是一个典型的例子——他们仅通过汽车登记表和电话薄来联系调查对象。在上个世纪 30 年代的美国,拥有汽车和电话的家庭终究是少数。这样的调查方式,最终得到了一份与真实情况相去甚远的预测。
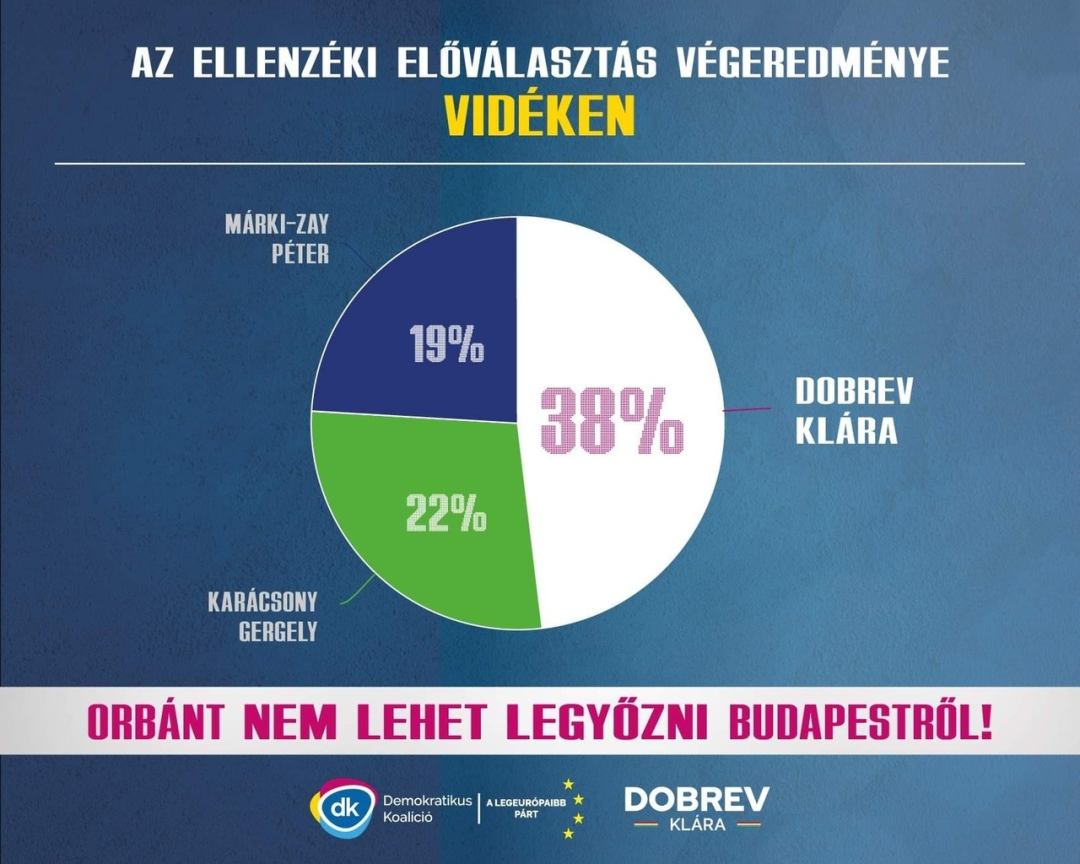
类似的偏差也常见于可视化上。例如下面这张匈牙利大选初选结果的可视化,通过简单相加我们可以轻易发现,三位候选人的累积支持比例并未达到 100%。除了计算错误,这样的可视化还遗漏了其他重要的信息:剩下的 21% 的支持率中还包括哪些候选人,其中是否还有具有影响力的候选人?更多重要的信息,在这张可视化中被丢弃了。
对数据更完整的呈现方式,可以借鉴纽约时报的报道——“疫情的参差”。作者力求用更丰富的可视化细节,尽可能地帮助读者一揽全局。首先,他们将来自不同地理位置、经济发展水平的城市疫情折线图堆叠到同一个坐标系内;然后根据不同的疫苗普及率与感染人数之间的关系,将对应的折线标亮成不同的颜色。
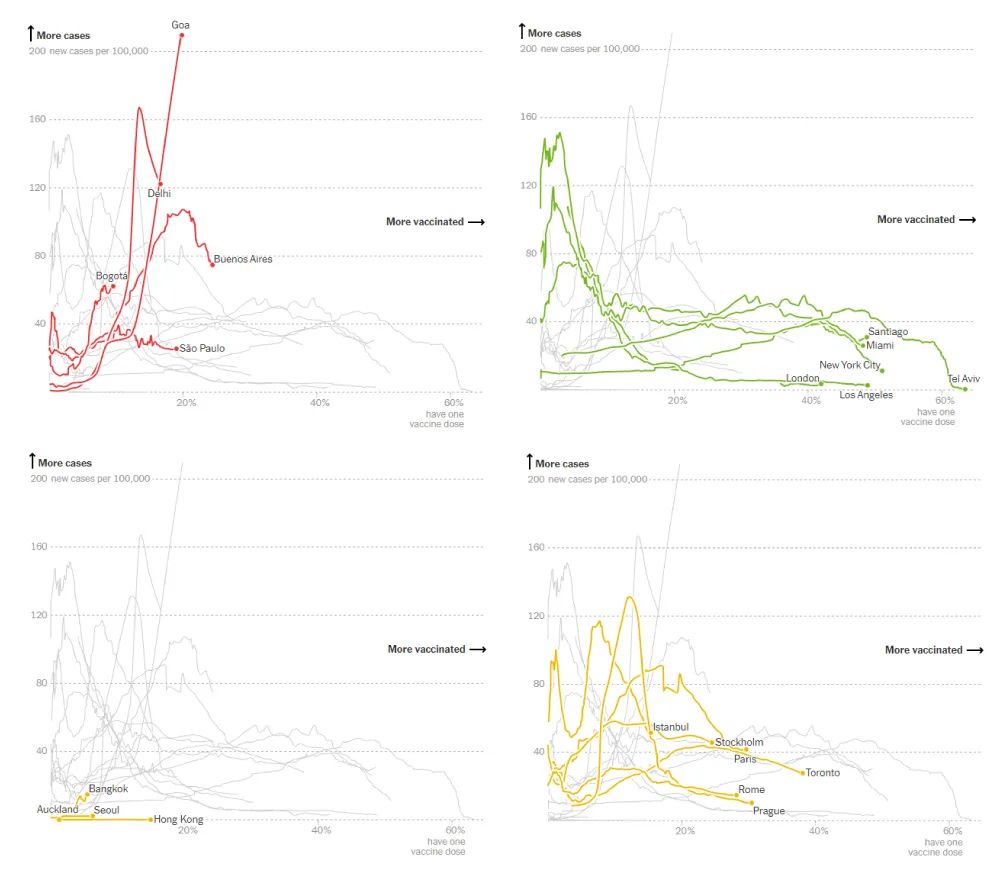
由此,读者可以直观且全面地观察全球范围内,疫苗普及率和疫情扩散之间的相关性。以及经济发展水平和疫苗普及率之间的关系,理解疫苗分配不公将导致疫情发展失衡。
在理解可视化时我们应该带着一些质疑的眼光——一张图表到底有没有遗漏什么信息呢?在《拼凑真相》中,作者也给出了这样的建议:
在别人给我们提供数据时,我们可以,也应该记得问一下,哪些人或哪些内容可能遗漏了。
(职场责编:拓荒牛
 晋ICP备17002471号-6
晋ICP备17002471号-6