Github Copilot和Codeium等编程助手正在改变软件工程领域。
这些编程助手可以根据现有代码和工程师的提示生成新的代码行或整个代码块建议,将其作为一种高级自动补全功能。
初看之下,这样的结果很有吸引力。编程助手已经在改变一些程序员的工作现状,并且也在改变编程的教学方式。然而,我们需要回答的问题是:这种生成式人工智能到底只是一种徒有其名的辅助工具,还是真的能给开发人员的工作流程带来实质性的改变?
在超威半导体公司(AMD),虽然我们专注于设计和开发中央处理器(CPU)、图形处理器(GPU)及其他计算芯片,但我们所做的很多工作都是底层软件开发,这些软件能够将操作系统和其他客户软件与我们的硬件无缝集成。实际上,大约一半的AMD工程师都是软件工程师,这在同体量公司中并非个例。当然,我们对了解人工智能在软件开发过程中的潜力有着浓厚的兴趣。
为了了解人工智能最大的用武之地及其发挥作用的方式,最近我们对软件开发方式进行了几次深入的研究,并且有了惊人的发现:编程助手擅长的任务类型(编写代码)实际上只是软件工程师工作的一小部分。我们的开发人员将大部分精力投入到了一系列任务中,包括学习新工具和技术、对问题进行分类、调试相关问题,以及测试软件。
即使是在编写代码这一编程助手擅长的基本任务中,我们也发现,编程助手带来的收益是递减的,它们对从事基本任务的初级开发人员来说非常有用,但对从事专门任务的高级开发人员来说帮助不大。
我们得出的结论是,要以一种真正变革性的方式使用人工智能,就不能把自己局限在编程助手上。我们需要更全面地考量整个软件开发生命周期,并在每个阶段采用最有帮助的工具。因此,我们正在针对特定代码库微调可用的编程助手,使其即使对高级开发人员也能产生更大的帮助作用。不过,我们也在调整大语言模型,用于执行软件开发的其他部分,例如审查和优化代码以及生成错误报告。我们正在将研究范围拓宽到大语言模型和生成式人工智能之外。我们发现,使用能够对内容进行分类而不是生成内容的判别式人工智能,在测试中大有裨益,特别是检查电子游戏在软件和硬件中的运行情况时。
短期内,我们的目标是在软件开发生命周期的每个阶段利用人工智能。我们预计,未来几年内,这一策略能够将我们的生产力提高25%。从长远来看,我们希望不局限于在每个阶段利用单一人工智能助手,而是将其结合起来,形成一个自主软件开发机器,当然,在这个过程中也会有人类参与。
我们意识到,即使沿着这条推行人工智能的道路坚持不懈地走下去,也需要仔细审查使用人工智能可能带来的威胁和风险。有了这些洞见,我们将得以充分发挥人工智能的潜力。以下是我们的经验。
GitHub研究建议,使用GitHub Cop-ilot,开发人员能够将生产力翻倍。在这一前景的吸引下,我们于2023年9月向AMD的开发人员提供了GitHub Copilot。半年后,我们对这些工程师进行了调研以评估助手工具的有效性。
我们监控了工程师对GitHub Copilot的使用情况,并将用户分为了两类:活跃用户(每天使用Copilot)和偶尔使用者(每周使用几次)。我们期望大多数开发人员都是活跃用户。然而,我们却发现活跃用户的占比不到50%。此外,我们通过软件审查发现,对于执行较简单编程任务的初级开发人员而言,人工智能带来了显著的生产力提高。我们观察到,对于处理复杂代码结构的高级工程师而言,人工智能实现的生产力增幅明显较低。这与管理咨询公司麦肯锡的研究结果一致。
被问到Copilot使用率相对较低的原因时,75%的工程师表示,如果Copilot的建议与他们的编码需求相关性更高,那么他们会更多地使用Copilot。这与GitHub的研究结果并不一定矛盾:AMD软件非常专业,因此可以理解的是,使用GitHub Copilot等采用公开数据进行训练的标准人工智能工具不会有太大的帮助作用。
例如,AMD的图形软件团队负责开发底层固件,将我们的GPU集成到计算机系统中;负责开发底层软件,将GPU集成到操作系统中;还负责开发软件以加速GPU上的图形和机器软件操作。这些代码都为应用程序(例如游戏、视频会议和浏览器)提供了使用GPU的基础。软件是AMD公司独有的,适配我们的产品,而标准辅助工具并没有针对我们的专有数据进行优化。
为了克服这个问题,我们需要使用内部数据集来训练工具,并开发专门针对AMD用例的工具。目前,我们正在使用AMD用例在内部训练一个编程助手,以期提高开发人员的采用率和最终的生产力。但了解调研结果后,我们也想知道:编写新代码在开发人员的工作中占比如何?为了回答这个问题,我们进一步研究了我们的软件开发生命周期。
AMD的软件开发生命周期包括5个阶段。
首先,我们会定义新产品或现有产品新版本的需求。然后,软件架构师会设计模块、结构和功能来满足定义的需求。下一步,软件工程师会进行开发,根据架构设计来实现软件代码以满足产品需求。在这个阶段,开发人员会编写新的代码行,但他们的工作并不局限于此,他们还可能重构现有代码、测试其编写的代码,并使其接受代码审查。
接下来,测试阶段正式开始。在编写了执行特定功能的代码之后,开发人员会编写一个单元测试或模块测试程序,来验证新代码能否按要求运行。在大型开发团队中,许多模块是并行开发或修改的。在集成到更大的系统中时,必须确认所有新代码都不会产生问题。该过程通过集成测试验证,通常每晚运行。此后,团队会对整个系统进行回归测试,以确认加入新功能之后系统也能像之前一样良好地运行。而且系统还要经过功能测试以确认新旧功能,并经过压力测试以确认整个系统的可靠性和稳健性。
最后,在成功完成所有测试后,产品发布并进入支持阶段。
一个新的AMD Adrenalin图形软件包的标准发布过程平均需要6个月。随后是密集程度不高的支持阶段,还需要3到6个月。为了确定每个阶段有多少工程师参与其中,我们跟踪了一次这样的发布过程。开发和测试阶段是目前为止资源最密集的阶段,每个阶段有60名工程师参与。20名工程师参与了支持阶段,10名工程师参与了设计阶段,5名工程师参与了定义阶段。
由于开发和测试阶段比其他任何阶段都需要更多的工程师,因此我们决定对开发和测试团队进行调研,以了解其每天各项工作的耗时情况。调研结果再次令我们惊讶:即使是在开发和测试阶段,开发和测试新代码总共也只占开发人员工作的40%。
软件工程师一天中另外60%的时间需要处理多项工作:约10%的时间用于学习新技术,约20%的时间用于分类和调试问题,近20%的时间用于审查和优化其编写的代码,约10%的时间用于代码归档。
在这些任务中,许多任务都需要高度专业化的硬件和操作系统,而现有编程助手并不具备。此次评估再次深刻提示我们:要突破基本代码补全的局限,利用人工智能显著改善软件开发生命周期。
如今,有关大语言模型和图像生成器等生成式人工智能的报道非常多。不过我们发现,判别式人工智能这种更老旧的人工智能可以显著提高生产率。生成式人工智能旨在创造新的内容,而判别式人工智能则是对现有内容进行分类,例如识别图像中是猫还是狗,或者根据风格识别著名作家。
我们在测试阶段广泛使用了生成式人工智能,特别是在功能测试中。进行功能测试时,我们会在一系列实际条件下测试软件的行为。在AMD,我们在许多产品、操作系统、应用程序和游戏中都测试了我们的图形软件。
例如,我们使用一个数据集训练了一组深度卷积神经网络(CNN),该数据集收集了超过2万张“黄金”图像(没有缺陷并且可以通过测试的图像)以及2000张扭曲的图像。卷积神经网络学会了识别图像中的视觉伪影,并且会自动向开发人员提交错误报告。
通过结合判别式人工智能和生成式人工智能实现自主玩电子游戏,我们进一步提高了测试效率。玩游戏涵盖了许多元素,包括理解屏幕菜单和菜单导航、在游戏世界中导航和移动角色、理解游戏目标和行动以便在游戏中取得进展等。

虽然游戏各有不同,但动作游戏的运行方式基本上都是以文本屏幕开始,让玩家选择选项。我们会使用生成式人工智能大型视觉模型来理解屏幕上的文本,导航菜单以进行配置,然后开始游戏。一旦可玩角色进入游戏,我们就会使用判别式人工智能来识别屏幕上的相关对象,了解友方或敌方不可玩的角色,并引导每个角色走向正确的方向或执行特定的动作。
为了在游戏中导航,我们使用了几种技术,例如,使用生成式人工智能来阅读和理解游戏中的目标,使用判别式人工智能来确定迷你地图和地形特征。生成式人工智能还可以用于根据所收集到的信息预测最佳策略。
总的来说,在功能测试阶段使用人工智能减少了15%的手动测试工作,并且将我们可以测试的场景数量增加了20%。不过我们相信,这只是开始。我们还在开发人工智能工具,用于协助代码审查和优化、问题分类和调试,以及代码测试的更多方面。
在审查和优化方面,我们正在根据自己的代码库和文档微调现有的生成式人工智能,为软件工程师打造专门的工具。我们开始使用这些微调后的模型来自动审查现有代码的复杂性、编码标准和最佳实践,目标是提供类似人类的代码审查和标记机会领域。
同理,在分类和调试时,我们分析了要理解和解决的问题,以及开发人员需要哪些类型的信息,然后开发了一个新的工具来帮助完成这一步。我们实现了分类和调试信息的检索和处理自动化;将一系列具有相关上下文的提示输入到了一个大语言模型中,并分析了相关信息,以确定问题可能的根本原因,从而提出工作流的下一步建议。此外,我们还计划使用生成式人工智能,以集成到开发人员工作流程的方式,针对特定功能创建单元测试和模块测试。
目前这些工具正在开发中,并在选定的团队中经受试验。我们预计,一旦完全采用这些工具,且这些工具可以协同工作并无缝集成到开发人员的环境中,整个团队的生产力将提高25%以上。
不过,25%的提升前景并非毫无风险。我们特别关注人工智能使用中的几个道德和法律问题。
首先,我们对使用人工智能建议持谨慎态度,以防侵犯他人的知识产权。任何生成式人工智能软件开发工具都必须建立在数据集(通常是源代码)的基础之上,并且往往是开源的。我们采用的任何人工智能工具必须尊重且正确使用第三方知识产权,工具不得输出侵犯该知识产权的内容。因此,我们需要过滤器和保护措施来确保不产生此类风险。
第二,我们担心在使用公开的人工智能工具时,自己的知识产权可能会无意中泄露。例如,某些生成式人工智能工具可能会接受你的源代码输入,并将其合并到其更大的训练数据集中。如果它是公开可用的工具,那么它就有可能会向使用该工具的其他人公开你的专有源代码或其他知识产权。
第三,我们必须认识到,人工智能也会犯错。大语言模型尤其容易产生幻觉或提供虚假信息。即使我们将更多的任务交给人工智能代理,在可预见的未来,我们也需要让人类参与其中。
最后,我们也担心人工智能可能带来偏见。在软件开发应用程序中,我们必须确保人工智能的建议不会造成不公平,人工智能生成的代码在人类道德原则的范围内,而且不会有任何歧视。这也是负责任的人工智能必须有人类参与的另一个原因。
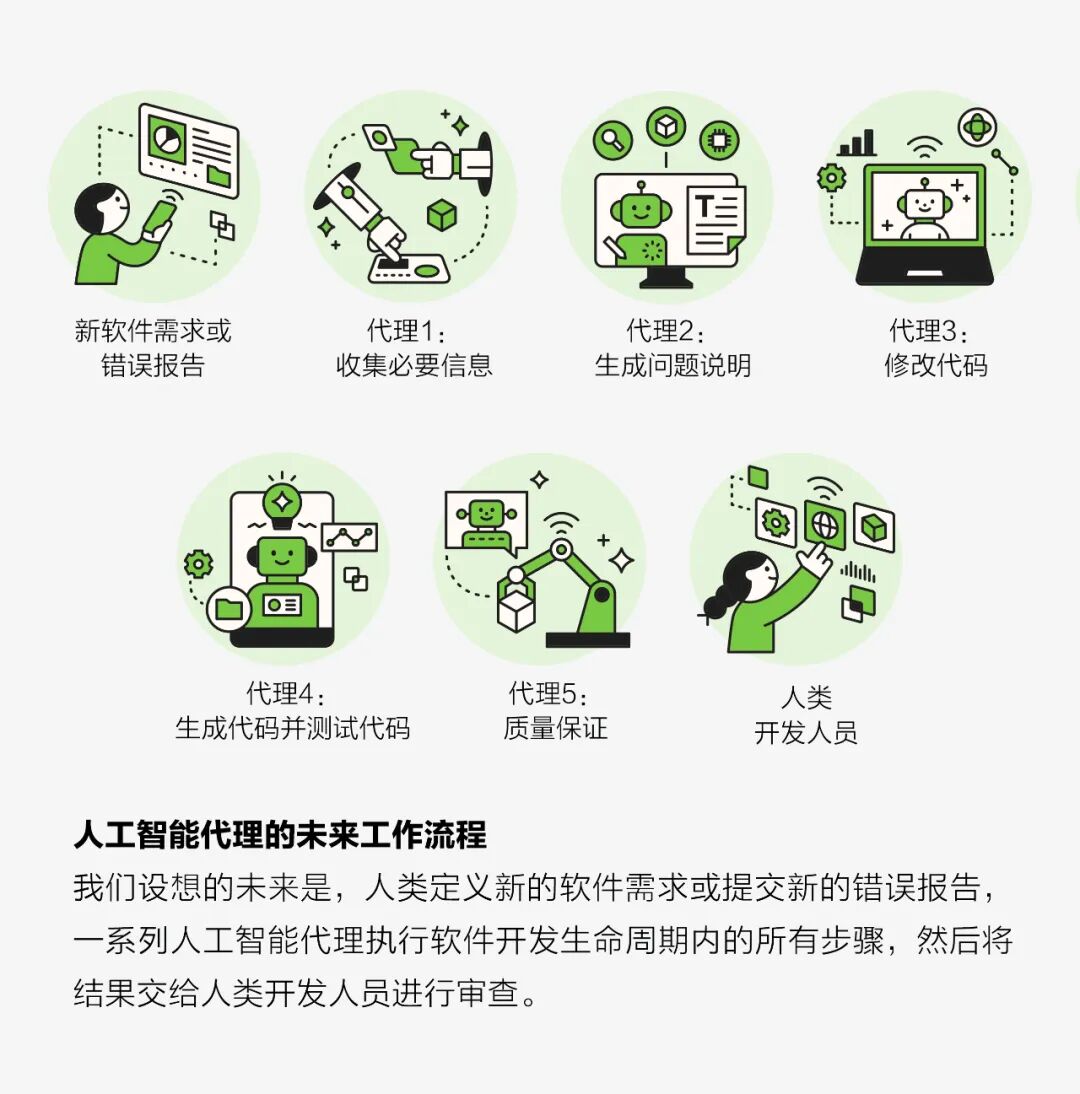
考虑到以上这些问题,我们计划在整个软件开发生命周期中继续开发人工智能的功能。目前,我们正在构建人工智能代理这种单独工具,它可以协助开发人员完成所有日常工作,包括学习、代码生成、代码审查、测试生成、分类和调试。我们从简单场景开始,将逐步发展这些工具,使其能够处理更复杂的场景。一旦这些工具成熟,我们就会开始将人工智能代理融入完整的工作流程。
我们设想的未来是,出现新的软件需求,或者提交问题报告时,人工智能代理可以自动找到相关信息,理解手头的任务,生成相关代码,并测试、审查和评估代码,然后循环这些步骤,直到系统找到良好的家解决方案,最后提交给人类开发人员。
即使在这种情况下,也需要软件工程师来审查和监督人工智能的工作。但软件开发人员的角色将发生转变。我们将不再编写软件代码,而是对代理进行编程并编写代理之间的接口。本着负责任人工智能的精神,人类将进行监督。
作者:Andrej Zdravkovic
(科技责编:拓荒牛
 晋ICP备17002471号-6
晋ICP备17002471号-6