Fastly发现网站AI流量多来自爬虫,即时截取却成最大压力源
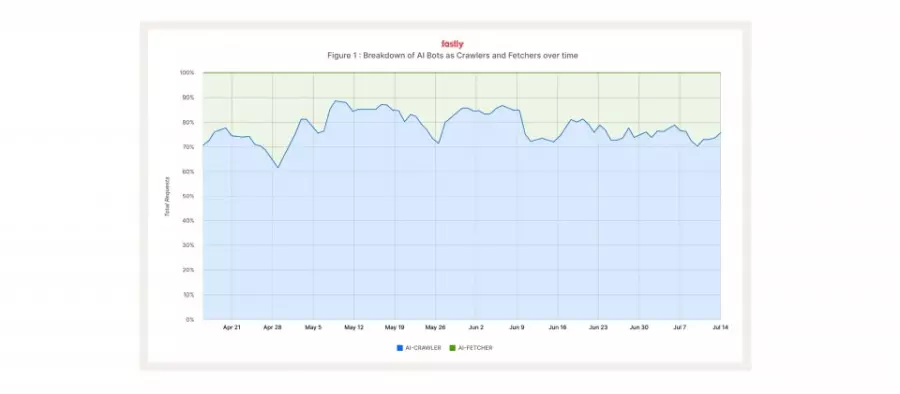
云计算企业Fastly在2025第二季的Threat Insights报告指出,人工智能机器人正在改变网站流量结构,虽然人工智能机器人流量的80%来自爬虫,不过,真正对基础设施造成压力的是来自模型推理阶段的即时截取。即时截取工具在高峰甚至可对同一网站发出每分钟3.9万次请求,远高于最大训练爬虫约每分钟1千次,可能对未加以防护的网站形成类似DDoS的冲击。
根据Fastly的数据,人工智能爬虫流量主要由Meta、Google与OpenAI三大企业产生,合计占比高达95%,其中Meta单独贡献了52%,Google为23%,OpenAI则约20%。在即时截取方面,OpenAI的ChatGPT-User与OAI-SearchBot为绝对大宗,合计占即时截取工具流量近98%。
以区域来看,北美网站接收的人工智能流量接近90%属于爬虫,欧洲、中东与非洲地区(EMEA)情况则相反,即时截取工具占59%,亚太(APAC)与拉丁美洲以爬虫为主,但比例相对较低。产业面也呈现分化,教育与媒体娱乐流量以即时截取工具为主,分别为68%与54%,更容易受到即时查询的高并行影响,相较之下,电商、医疗与公共部门超过90%流量为爬虫。
在内容来源方面,OpenAI的GPTBot虽不是最大流量来源,但覆盖范围最广,以触及的独立网站数计算,其覆盖率高达95%,采取的是广度策略,而Meta策略则是深度索引,流量庞大但命中网站数较少。
Common Crawl的CCBot特色则为每月两星期的规律抓取,覆盖约63%的人工智能爬虫触及网站,长期被学术界与小型团队用于研究数据搜集。整体而言,训练数据仍明显偏重北美,在亚太地区,网站数据则主要由日本的软银(SoftBank)与NICT索引,这显示亚太数据并非平均分布,而是倾向集中于日本,进一步影响模型可能展现出较接近日本的资讯面貌。
这些趋势代表网站需要在政策与技术上双重准备,策略层面上,官方建议,可通过robots.txt与X-Robots-Tag明确声明允许或拒绝的范围,并要求人工智能爬虫提供可验证的身份资讯,如公开IP与反向DNS。技术层面则需导入速率限制、来源挑战与即时监测,确保能将正常的自动化与恶意或伪装流量加以区隔。
Fastly强调,这些结论来自其对超过13万个应用与API的流量分析样本,每月平均涵盖6.5兆请求。
(科技责编:拓荒牛








 晋ICP备17002471号-6
晋ICP备17002471号-6