一场演讲引爆5万亿市值!黄仁勋展露野心,英伟达加冕全球科技新王
首次全面展露“连接两个世界”的野心
作者/ IT 时报贾天荣
编辑/ 郝俊慧 孙妍
美东时间 10 月 29 日,英伟达股价开盘即涨 3.4%,公司市值突破 5 万亿美元,成为全球首家达到这一里程碑的公司,此时距离英伟达市值突破 4 万亿美元仅过去四个月。
就在前一天,英伟达在华盛顿举行了 GTC(GPU 技术大会),黄仁勋的主题演讲成为这场历史性突破的催化剂。
这场演讲到底有什么魔力?
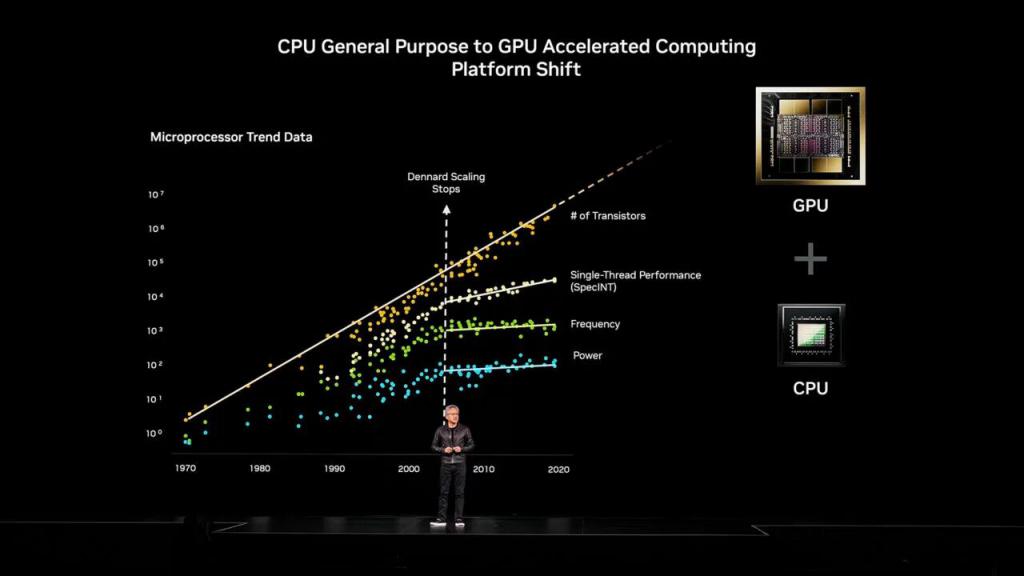
演讲中,黄仁勋再次强调摩尔定律(Moore's Law)已正式终结。当前是一个 AI 算力需求呈双重指数级增长的时代,更是一场新的算力竞赛起点。
本届 GTC 大会上,他以极具感染力的方式,将一个复杂的科技趋势转化为一个清晰、紧迫且充满机遇的宏大叙事——我们正站在一个历史性的拐点,旧规则已死,一个由 AI 定义的新计算时代正在爆发。
在黄仁勋勾勒的 AI 蓝图中,“连接”是隐藏在整场演讲背后的关键词,无论是超级芯片、超级计算机、超级 AI 工厂,还是量智融合计算,核心都是解决连接问题,英伟达正试图成为未来智能世界的“连接者”。
连接算力
从芯片到国家 AI 基础设施
超级芯片,显然是英伟达成为“连接者”的基石。而由超级芯片连接构成的超级计算机,也成为英伟达通向新时代的地基。
GTC 上,下一代 Vera Rubin 超级芯片(Superchip)首次公开亮相。从架构层面看,Vera Rubin 是英伟达迄今最复杂的计算平台,整合了一颗 Vera CPU 与两颗巨大的 Rubin GPU,并配备了最多 32 个 LPDDR 内存插槽。

Vera Rubin 分为普通版 Vera Rubin NVL144 和 Ultra 版 NVL576,这是继英伟达在 2024 年 3 月第一次推出超节点 GB200 NVL72 之后,再次明确下一代超节点的技术指标。
NVL144 意味着将在单一机架中连接 144 颗 GPU,提供 3.6 exaflops FP4 推理和 1.2 exaflops FP8 训练能力,相比前代 GB300 的 NVL72 提升约 3.3 倍;将在 2027 年下半年推出的 Rubin Ultra NVL576,则将可连接的 GPU 数量扩展到 576,FP4 推理算力可以达到 15 exaflops,FP8 训练算力达 5 exaflops,相较 GB300 NVL72 提升 14 倍。
超节点架构已成为 AI 数据中心基础设施的核心方向。今年 9 月,华为在全联接大会上宣布了昇腾的超节点计划—— Atlas950 将支持 8192 张昇腾卡,2027 年计划扩展至 15488 芯片集群。
当“摩尔定律”逐渐失效后,单芯片能力无法短期提升,依靠“连接”打造超级芯片,或者更大规模的超级计算机,已经是 AI 时代的必经之路。
黄仁勋当天宣布,英伟达与美国能源部达成战略合作,联合甲骨文公司,将在阿贡国家实验室共同建设七台新一代超级计算机,打造能源部体系内规模最大的 AI 超级计算机集群。
这一超级计算网络包含两大核心系统:Solstice 系统将部署 10 万颗英伟达 Blackwell GPU,建成后将成为全球规模最大、面向公共研究领域的智能体科学平台;Equinox 系统配备 1 万颗 Blackwell GPU,提供高达 2200 EFLOPS 的 AI 算力,专门服务于前沿科学计算、模拟仿真与开放研究。
连接未来
从 6G 到量子计算
现如今,云计算被视为计算机网络领域的一次革命。它的出现,让社会的工作方式和商业模式都发生了巨变。
“互联网实现了通信,而像 AWS 这样的公司,已在互联网之上建立了云计算系统。”黄仁勋在 GTC 大会上宣告,“现在,英伟达要在无线电信网络上做同样的事情。”目标是将云计算的能力,直接“下沉”到数据中心无法覆盖的边缘场景。因为,电信行业拥有人工智能最宝贵的资源——边缘计算,也就是数据产生的地方,而基站遍布世界每个角落。
为此,英伟达为老牌通信设备厂商——诺基亚投资 10 亿美元,并发布了以美国为核心的 AI 原生 6G 无线协议栈—— NVIDIA ARC。“诺基亚将把 NVIDIA-ARC 作为未来的基站架构,NVIDIA-ARC 还与当前的诺基亚基站架构 AirScale 兼容。”黄仁勋在演讲中称,将用 6G 和 AI 升级数以百万计的基站,要用 AI 技术让无线通信更高效。
根据其构想,电信运营商可以在同一基础设施上推出面向 6G 的新一代 AI 服务,支持数十亿辆汽车、机器人、无人机以及 AR/VR 眼镜等新型终端设备的连接需求,这些设备均要求在边缘侧具备强大的连接性、计算能力和感知能力。
“电信是我们经济和国家安全的命脉。”黄仁勋直言不讳,当前全球正处于新一轮“平台级转型”的关键窗口,这也是美国科技产业“重返赛场的千载难逢机遇”。
在另一个前沿领域——量子计算领域,英伟达同样以“连接”作为破解难题的钥匙,正式发布了 NVQLink ——一种全新的互连架构,可将量子处理器(QPU)与英伟达 GPU 直接相连。

NVQLink 希望解决的是量子计算当前面临的核心挑战——提升量子纠错率。量子比特门在计算时,极易受到噪声和退相干效应的影响,而通过 NVQLink,可以达到近乎实时的反馈并完成纠错,从而使量子计算机可控的量子比特数量级从现在的数百提升至数万,甚至百万级,并实现通用量子计算。
“ NVQLink 正是连接量子与经典超级计算机的罗塞塔石碑——将二者融合为一个统一、连贯的整体系统,标志着量子 -GPU 计算时代的开启。”黄仁勋透露,已有 17 家量子处理器制造商、5 家量子控制系统厂商和 9 家国家实验室支持 NVQLink。

连接虚实
从数字孪生到“物理 AI ”的平行世界
将视角转向现实世界的应用,英伟达给出的答案是“物理 AI(Physical AI)”“ AI 工厂(AI Factory)”。在黄仁勋眼中,机器人、汽车等都属于物理 AI 范畴,AI 的下一个阶段就是物理 AI。
谈及此事时,大屏幕上播放的是一个看似动画实则由 Omniverse(英伟达推出的工业数字化平台)实时模拟生成的片段。“记住,这不是电影,而是模拟。”黄仁勋强调,“数字孪生工厂、仓库、手术室等—— AI 正在实时学习如何理解和操作现实世界。”
“我们已经与众多合作伙伴一起,在打造具备物理 AI 的工厂。”黄仁勋详细地举例描绘了物理 AI 工厂的运转方式——在休斯敦,富士康正在建设一座最先进的机器人生产基地,用于制造英伟达 AI 基础设施系统。
首先,工厂在 Omniverse 中“数字化诞生”。富士康工程师基于“西门子数字孪生解决方案”组装虚拟工厂,所有系统——机械、电气、管道——都在施工前完成虚拟验证;随后,在 Isaac Sim 平台中,数字孪生工厂又成为训练与测试机器人 AI 的虚拟场景:发那科机械手组装 GB300 托盘模块,FII 灵巧机器人完成母线排安装,AMR 自主移动机器人负责运输测试。
富士康还利用 Omniverse 进行大规模传感器仿真,使机器人群能够协同作业。基于 NVIDIA Metropolis 与 Cosmos 构建的视觉 AI 智能体,可以从高空监测工厂运行,实时识别异常、安全隐患与质量问题。
“人们和机器人协同工作,这就是制造业的未来,工厂的未来。”黄仁勋提到,越来越多的企业正将数字孪生融入制造体系中,从卡特彼勒的重型设备,到强生的微创手术机器人;从 Agility Robotics 的仓储自动化,到迪士尼基于物理仿真的互动机器人;乃至马斯克的人形机器人项目——它们都在 Omniverse 中学习理解并操作现实世界。
在黄仁勋看来,AI 不是工具,AI 就是生产力的主体。AI 能够使用工具,这使其能够参与此前 IT 工具无法触及的全球经济领域。

连接生态
从自动驾驶到企业核心的全面渗透
随后,黄仁勋话锋一转,谈到另一类“机器人”——自动驾驶汽车:“轮式机器人正迎来拐点,机器人出租车本质上就是 AI 司机。”
当日,黄仁勋宣布:英伟达与 Uber 正共同构建面向未来的自动驾驶出行平台,计划自 2027 年起规模化部署约 10 万辆自动驾驶车辆。

这一雄心勃勃的项目将依托英伟达最新一代 DRIVE AGX Hyperion 10 平台。这是英伟达新的 L4 级自动驾驶平台,配备两颗 Thor 处理器(每颗约 2000 FP4 TFLOPS),传感器套件包含 14 个摄像头、9 个雷达、1 个激光雷达和 12 个超声波传感器,具备安全可靠、弹性扩展和软件定义三大特性。目前,梅赛德斯 · 奔驰已率先采用该架构,更多汽车品牌也即将加入。
黄仁勋描绘了未来的落地场景:“用户只需通过手机应用召唤,Hyperion 自动驾驶出租车就将如约而至,这套系统将在全球范围内实现人类驾驶员与机器人驾驶员的协同运营。”
英伟达在大会上还公布了与多家行业领先企业的合作,推动 AI 在具体场景中的应用。
比如,在生物医药方面,礼来与英伟达的合作将建设一台由超过 1000 块 Blackwell Ultra GPU 驱动的超级计算机,这是一个专门的计算基础设施,将大规模开发、训练和部署用于药物发现和开发的 AI 模型。
芯片、6G、量子计算、物理 AI、机器人、自动驾驶……在全球科技资本关注的焦点之中,英伟达的蓝图无处不在。
针对行业内的 AI 泡沫争议,黄仁勋明确反驳:“我不认为我们处于 AI 泡沫之中。我们正在使用不同的 AI 模型,并乐于为此付费。”
面对新的算力竞赛,黄仁勋似乎在一次次宣告,英伟达不再是单纯的技术供应商,通过其独特的技术架构和全球合作网络,它正在成为碳基世界与硅基世界的“连接者”。
排版/ 季嘉颖
图片/ 英伟达
来源/《IT 时报》公众号 vittimes
(科技责编:拓荒牛








 晋ICP备17002471号-6
晋ICP备17002471号-6