
在人工智能(AI)以前所未有的速度重塑全球科技版图的今天,高性能计算(HPC)与AI的结合已成为市场最炙手可热的焦点。对此,台湾美光先进封装暨测试运营副总裁张玉琳表示,高带宽内存(HBM)在AI时代扮演呃关键角色,其背后源自于极具挑战性的先进封装技术,特别是美光所坚持的TCB-NCF(热压合非导电胶膜)制程的独到之处与未来潜力。
张玉琳在Semicon Taiwan以“AI时代的HBM与先进封装”发布主题演讲时表示,随着AI模型从GPT-1到GPT-5的演进,训练所需的数据量(token)呈现了近百万倍的惊人增长,而模型参数也达到了数十万的规模。这对内存产生了前所未有的渴求。一颗HBM将会消耗掉三颗DRAM的产能,这使得全球DRAM的供应挑战变得极为严峻。

过去,GPU都是通过PCB板与GDDR6内存连接。如今,为了追求极致的性能,GPU与HBM内存被一同放置在如CoWoS或EMIB等先进的2.5D/3D堆栈平台上。这种架构确保了数据传输的最短路径与并行计算能力,并在散热和稳定性上获得了巨大提升。从早期的4层堆栈HMC,到现在业界热卖的8层、12层甚至16层堆栈的HBM3,显示出市场对于内存容量的需求,促使制造商不断挑战堆栈技术的极限。
张玉琳指出,HBM是连接内存与处理器距离最短、效率最高的方案。他解释,内存的基本单元即便使用了先进的高K介电质材料,依然需要实体空间,无论是水平扩展还是垂直堆栈。将其集成到采用极紫外光(EUV)等先进制程的逻辑芯片中,不仅成本效益极低,更会因高温产生漏电问题,影响性能。这正是为何内存、射频(RF)及高功率组件需要通过先进封装技术进行异质集成,而非单纯遵循摩尔定律进行微缩的原因。
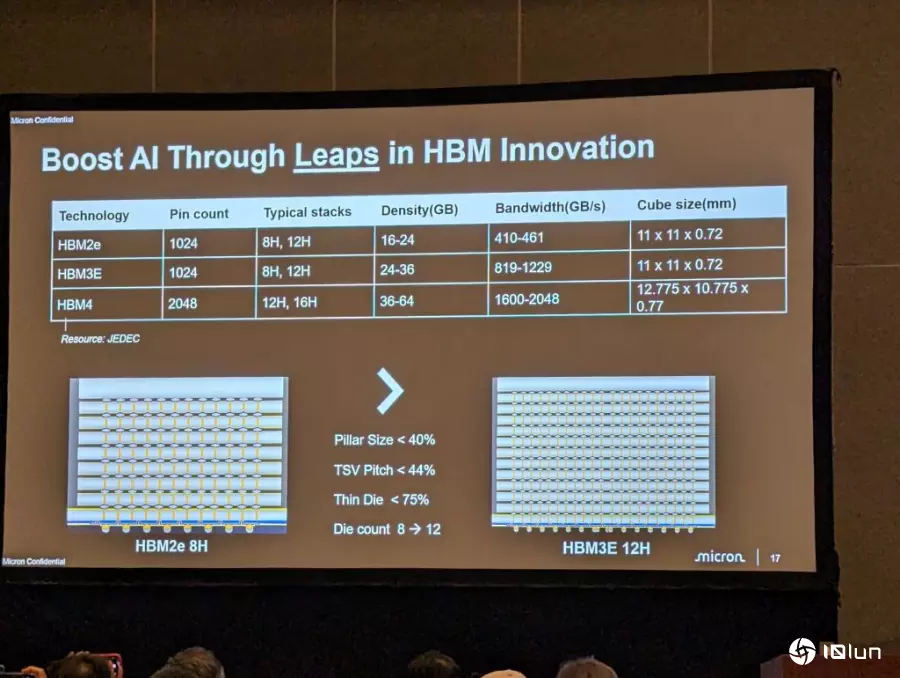
事实上,一片12英寸的芯片厚度约为775微米,而HBM3或HBM4单层芯片的厚度,甚至不到其百分之一。因此,根据物理定律,当厚度减半时,应力会增加八倍。若将厚度缩减至原来的二十分之一,所产生的应力将会是惊人的8,000倍。因此,处理这种极薄、极脆弱的芯片,就像在纸片上进行精密的建筑工程,但这也为产业带来了巨大的技术创新机会。从HBM2E到HBM3,接点间距(pitch)缩小了超过一半,而TSV(硅穿孔)的数量则增加了四倍。这些数据的背后,是AI性能得以飞跃式进展的根本原因,同时也给封装工程师带来了极其艰巨的“肮脏活”(dirty job)。
在众多封装技术路线中,美光是少数几家坚持采用TCB搭配NCF制程的公司。虽然这条路线对制程控制的要求极高,但也带来了独特的优势。尤其,相较于主流的底部填充胶制程,预先涂布的NCF在压合过程中更容易控制胶体的流动与气泡的产生。如果仅依赖毛细作用的底部填充,气泡很容易被困在芯片内部;而使用NCF,我们可以更好地将气泡向外排出。一旦产生气泡,将可能导致比接点本身更细微的桥接问题,进而引发短路与失效。
张玉琳强调,HBM的制造流程是一个失败哲学(Fail Philosophy)的展现。从芯片薄化、切割、堆栈到最终成型,整个过程包含数百个步骤,任何一个环节的微小失误,如芯片翘曲(warpage)、裂纹(crack)、或粒子污染,都会在后续的堆栈过程中被放大,并导致最终的失败。因此,整个流程的良率控制如同走钢索般困难。
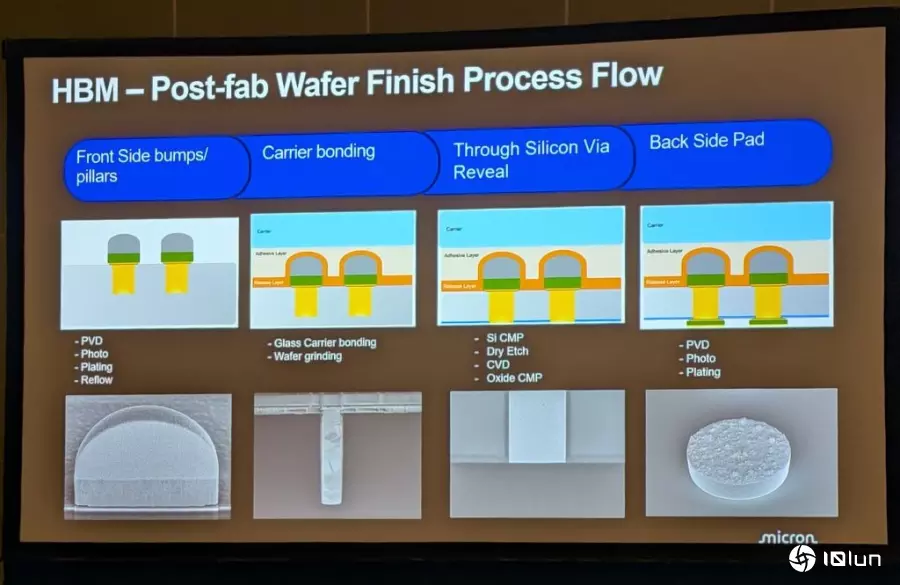
而美光凭借其过去在电子材料与半导体领域超过十年的研发经验,成功地带领团队克服了TCB-NCF制程的挑战,使其在市场上取得成功,也为美光在HBM领域创建了独特的技术壁垒。因此,半导体产业正处于一个转折点。过去,摩尔定律的微缩是推动产业发展的主要动力;而今天,先进封装技术的投资规模已与前端制程相当,成为延续性能增长的关键。
张玉琳最后指出,为了达到更高的速度、更大的带宽和更低的成本,产业正朝着扇出型(Fan-Out)封装、更精细的RDL(重布线层)、以及混合键合(Hybrid Bonding)等方向发展。然而,这些新技术也带来了新的问题,如翘曲、静电放电(ESD)等可靠性挑战。工程师在追求30%功耗降低或30%速度提升的同时,也必须面对更严峻的散热与应力管理问题。未来将由新材料、新架构设计以及先进封装解决方案共同驱动。从HBM内存到DRAM、SSD NAND闪存,再到低功耗DRAM模块,美光正致力于提供全方位的内存解决方案,以满足AI训练与推论的庞大数据需求,在这场由AI掀起的内存革命中,扮演不可或缺的关键角色。
(首图来源:科技新报摄)
(科技责编:拓荒牛








 晋ICP备17002471号-6
晋ICP备17002471号-6