GPT-5 没有惊喜,但信号拉满
OpenAI 难现往日辉煌。
新眸原创 · 作者 | 简瑜
在 GPT-4 发布两年之后,经历多次“跳票”的 GPT-5 终于在今日登场。
北京时间 8 月 8 日凌晨 1 点,OpenAI 举办了一场超过一小时的发布会,系统展示了 GPT-5 在智能水平、编程能力、任务推理等维度的性能迭代。
但相比此前 GPT-3 到 GPT-4 所带来的全方位升级,许多人表示,这次 GPT-5 并没有带来更多的惊喜,从发布会规模、产品亮点、到性能升级,都显得较为平庸,相较当前主流 SOTA 模型,提升幅度并不显著。
反倒是价格策略成了此次发布的最大亮点。GPT-5 的 API 调用价格仅为前几日发布的 Claude Opus 4.1 的 1/15,显著低于 Gemini 2.5 Pro,在当前大模型市场上展现出极强的性价比。
近两年,随着 AI 工具开始席卷各行各业,人们渴望 AI 能够取代重复繁琐的工作,也在担忧自己是否会被 AI 所取代,这也是 GPT-5 发布前备受关注的原因之一。但就目前 GPT-5 的能力突破来看,人类智能在通往 AGI 的路上仍有很长一段路要走。
回顾过去几年 GPT 的迭代历程,不仅是众多 AI 公司争相效仿的对象,也是整个大模型行业发展的缩影。而此次 GPT-5 相对平庸的表现,虽然打破了外界对大模型技术持续突破的惯性认知,但某种程度上,也在大多数人的意料之中。
相比 AI 兴起阶段大众对于大模型技术的过高展望,市场上有关大模型参数突破的讨论正势渐微弱。相比起技术突破,人们开始更加关心的是,AI 如何更有效地渗透进日常生活。
从 GPT1 到 GPT5
GPT 的未来要走向哪里?
自 2018 年 OpenAI 发布首个大模型 GPT-1 以来,GPT 系列已经走过了七年。
2020 年 GPT3 的出现,让大模型参数规模从 15 亿直接拓展到了 1750 亿,也因此通过“上下文学习”能力,摆脱了对大量标注数据的依赖,使大模型能够开始作为效率工具使用。
两年后,基于 GPT-3.5 构建的对话式模型 ChatGPT 上线,进一步推动大模型走入 C 端日常,成为通用 AI 应用的重要落地转折点。
随后 GPT-4 的全面升级,更是在实现万亿级模型参数的同时,让大模型在单纯文本输出的基础上,实现了图像的交互提升。
此后一年里,GPT 发布的多款模型,都在围绕图像、语音互动等多模态能力迭代; deepseek 的横空出世,将推理模型带向了大众视野,去年 OpenAI 接连发布了 O1、O3 系列产品,将复杂推理作为了性能优势,开始强调对科学、编程等专业领域的协助能力。
与此同时,围绕大模型参数量的宏大叙事开始逐渐消失,转变为对多模态、长文本等细节能力的追求,以及对医疗、教育等落地场景的讨论。正因如此,大模型产品形态也开始从单一模型转向了多版本并行。
截至目前,OpenAI 已构建起由 GPT 系列(主打对话交互)、O 系列(聚焦复杂推理)以及图像 / 视频生成模型(支撑多模态创作)组成的三大产品矩阵。
在本次升级的 GPT-5 中,GPT 进一步统一了 O 系列的推理能力和 GPT 的快速响应,相比较 deepseek 在模型使用时,自主选择是否使用深度思考模式,GPT-5 的区别在于能够自动判断对话类型。
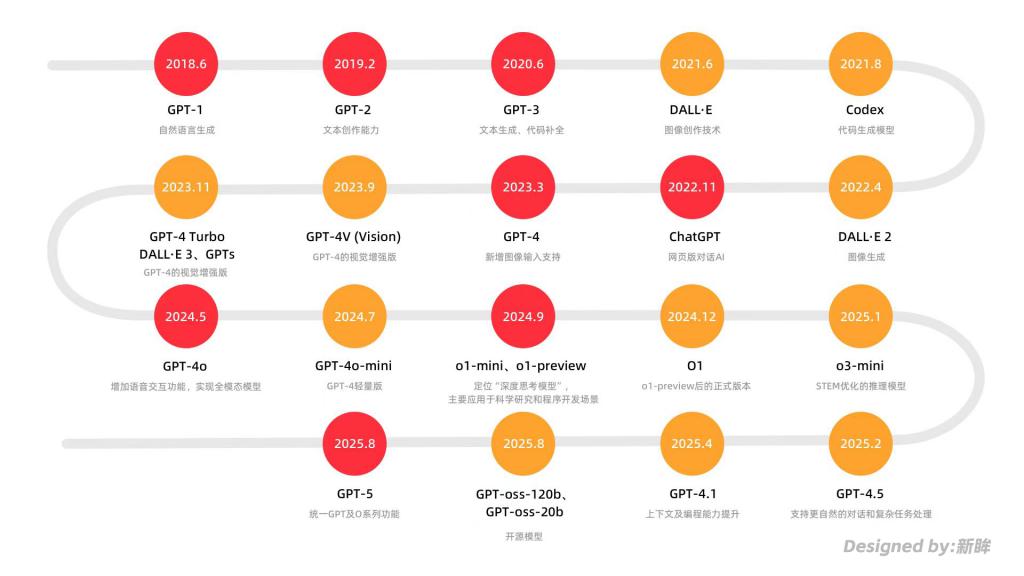
OpenAI 核心产品发布时间线
除此之外,在此次发布会中,OpenAI 首次同时推出了 4 个版本,标准版 GPT-5、轻量级的 GPT-5 mini 与 GPT-5 nano,以及面向企业与高级订阅用户的 GPT-5 Pro(需企业授权或月付 200 美元)。加深了按需定制、分层定价的 SaaS 化路径演进。
这种转变也意味着,对于 AI 公司来说,竞争的门槛不再仅是技术突破,还在于是否具备构建产品体验、搭建商业模型、整合跨界资源的综合能力。
GPT-5 难产真相:
大模型升级为何越来越难?
DeepSeek 上线所带来的用户量激增,不仅向外界证明了开源模型的商业化可行性,也进一步加深了大模型公司对“先发优势”的重视。当模型性能差距趋于收敛,前期对于用户心智的争夺上升为第一要义。
正因如此,随着 GPT-5 问世的风声不断,最近一段时间,各大厂商开始纷纷加速竞跑,相继推出新品。
字节在两个月前将豆包更新至 1.6 版本,阿里也在昨日推出了 Qwen3-4B-Instruct-2507 与 Thinking-2507 双版本,MiniMax 近几日发布了新一代语言生成模型 Speech 2.5,智谱也在上月底发布旗舰模型 GLM-4.5 ……一场集中式更新潮,给沉静许久的大模型赛道掀起了又一波浪潮。
但当我们把时间拉长来看,这波密集的模型上新趋势,距离上一次“百模大战”的盛景,已经过去了一年多。
大模型的更新趋势正在逐渐放缓。不仅如此,相较 GPT-3 到 GPT-4 参数暴涨、多模态突破、上下文显著增强的跃迁,近期多款新品的提升幅度也显得颇为有限,大多数模型的升级和 GPT-5 一样乏善可陈。
很多人把背后的原因归结为数据瓶颈。
去年万众瞩目的 Orion,项目开发时长超过了 18 个月,曾经被寄予厚望,原计划作为 GPT-5 推出。结果在验证时,性能却远未达到预期,最终只能被降级成 GPT-4.5,在今年 2 月默默上线。
据业内人士称,Orion 之所以失败,最核心的原因在于,团队摸到了预训练阶段的天花板。随着训练数据的不断扩充,高质量网络数据存量不断减少,直接导致了模型训练效果的下降。
除此之外,随着大模型参数量不断增加,硬件水平所带来的掣肘也在越发放大,据媒体报道,有开发人员透露,OpenAI 在去年年底所推出的推理模型 O3,之所以能够实现核心的性能提升,主要依赖于使用更多的英伟达芯片进行开发。
更进一步的问题在于,大众对于 AI 幻觉、AI 味的抵制正在呈现更为激进的态势。
(科技责编:拓荒牛








 晋ICP备17002471号-6
晋ICP备17002471号-6