2025年7月22日,在第八届智能辅助驾驶大会上,地平线芯片产品总监沈建指出,随着电子电气架构向中央集成与计算阶段演进,辅助驾驶算法与芯片面临更高要求,尤其是端到端与大模型技术的应用,使得芯片需具备高算力、高带宽和低延迟特性。他介绍到,地平线通过提升单芯片算力、优化系统效率及降低功耗等措施,积极应对这些挑战。
沈建还表示,地平线在芯片架构上不断创新,历经三代演进至Nash架构,实现了CNN和Transformer处理性能的显著提升,并解决了Memory Wall问题。此外,地平线的征程6系列芯片全阶覆盖高、中、低三档市场,其中J6P芯片算力高达560 TOPS,将于年内量产。

沈建|地平线芯片产品总监
以下为演讲内容整理:
地平线是全场景辅助驾驶领域的全球领导者。公司以技术为导向,现有研发人员超2000人,专利数量也有2000余项。公司在国际挑战赛及顶级学术会议上屡获佳绩,相关成果在辅助驾驶领域广受行业认可。商业化方面,截至今年第一季度,征程系列出货量已突破800万套,成绩斐然。
市场占有率方面,2023年,公司在自主品牌辅助驾驶解决方案市场中市占率位居行业第二。至2024年,公司市占率进一步提升,超过33%,每三台配备辅助驾驶系统的车辆中,就有一台采用地平线的解决方案。
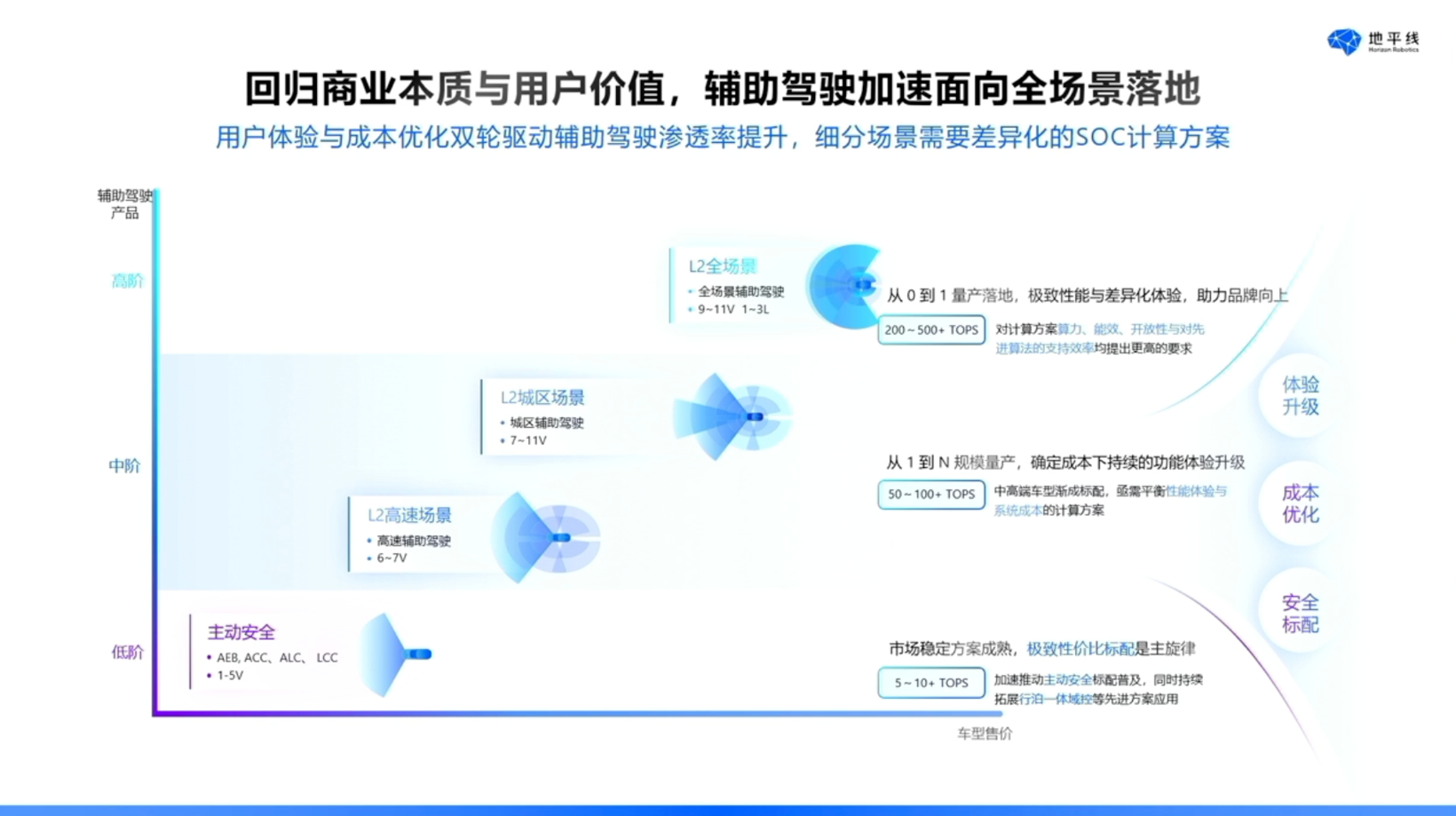
关于当前的行业发展趋势,从产品维度来看,目前市场可划分为高、中、低三档。低阶即入门级产品,该领域已基本成为红海市场,其核心诉求在于安全与性价比。中阶产品方面,随着去年及今年辅助驾驶普及进程的加速,预计在2025年至2026年,中阶产品出货量将发生质变,渗透率也将迅速提升。高阶产品领域,国内企业与特斯拉在高阶辅助驾驶的探索上从未停歇。
得益于各大厂商在端到端与大模型技术方面的努力,行业在各类场景及corner case上取得了显著进步,用户体验也大幅提升。然而,与人类驾驶水平或理想体验相比,仍存在一定差距,需持续努力与探索。
图源:演讲嘉宾素材
从多个维度分析,我们认为有三点至关重要。一是安全,无论高中低档产品,均需将安全置于首位。二是辅助驾驶的渗透率,当前及未来两三年内,其渗透率预计将维持高位,这意味着对域控制器及一体机的成本要求将日益提升。三是随着渗透率的提高,辅助驾驶的使用人群将不断扩大,进而对用户体验提出更高要求。若用户体验持续优化,则辅助驾驶的普及程度将进一步提升,这也是全行业共同追求的目标。
系统层面,电子电气架构历经多年演进,已从分布式架构发展至区域控制,进而迈向中央集成与中央计算阶段。电子电气架构的变革有效降低了整车的成本。此外,为提升辅助驾驶体验,各类异构计算单元的ECU正逐步向中央计算的SoC方向演进。这一演进对于降低成本及提升辅助驾驶体验具有实际意义。
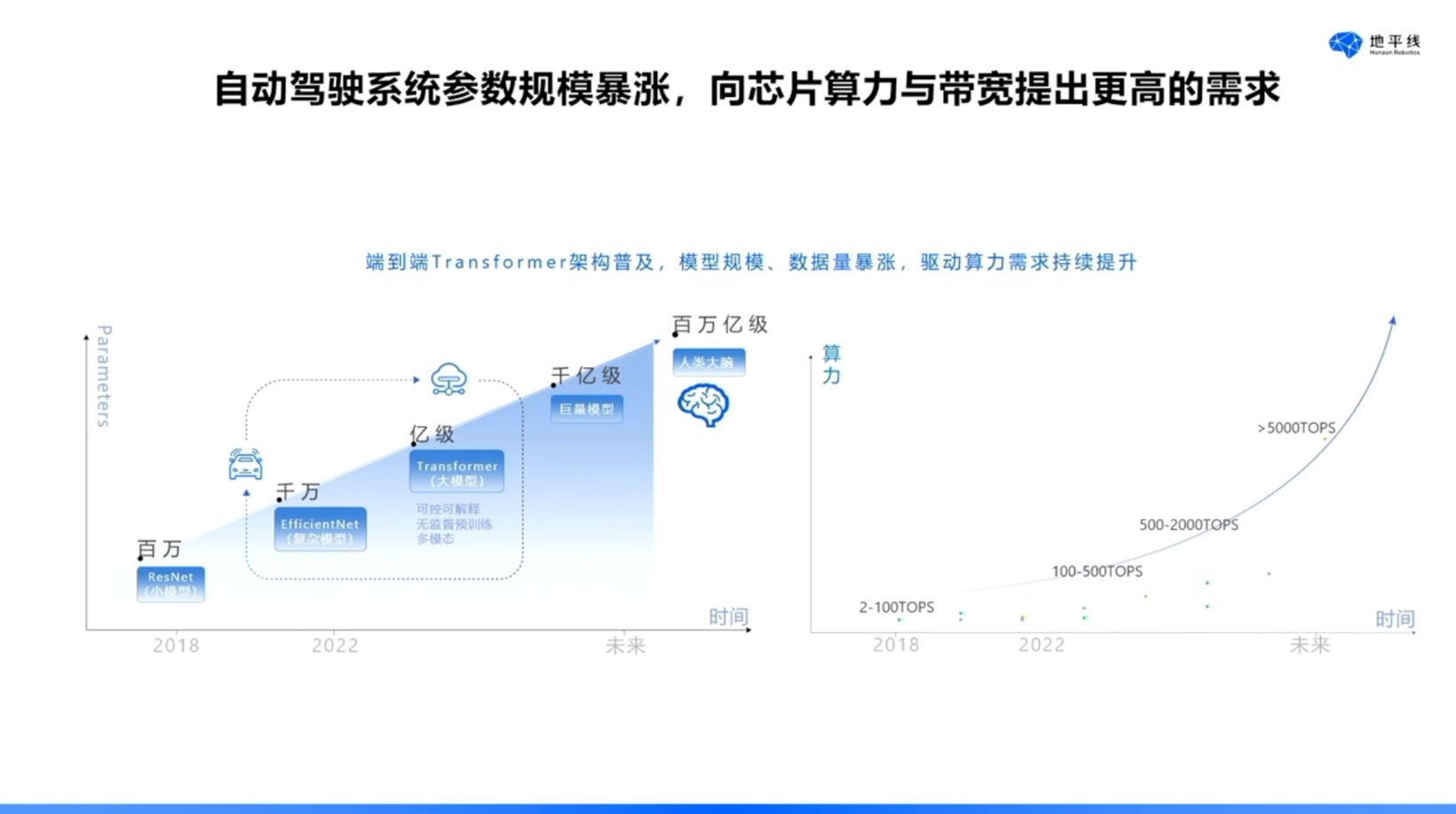
回归辅助驾驶算法与芯片本身,在 2024、2025 年相关讨论中,“端到端”与“大模型”是两个高频词汇,其中涉及 VLM、VLA 等技术。这些技术在提升辅助驾驶体验方面发挥了显著作用,但其代价亦不容忽视。这些模型的参数规模极为庞大,基本达到零点几亿级别,领先的技术模型参数规模更已达到数亿级别。如此庞大的模型参数对芯片性能提出了更高要求。此外,当前多数系统的帧率仍处于10~20帧水平,但预计在未来将逐步提升至更高帧率。因此,从算力层面来看,芯片需满足日益增长的性能需求。
值得注意的是,无论是端到端技术还是大模型,其底层架构均基于Transformer。Transformer作为一种带宽敏感型网络,随着参数量和帧率的增加,对芯片带宽的要求也显著提升。我们认为下一代芯片需具备高算力、高带宽和低延迟三大核心特性。
图源:演讲嘉宾素材
针对以上问题,我们认为首先需实现单芯片算力的有效突破。提升单芯片算力最直观的思路是先提升单代芯片性能,之后通过Chiplet技术等横向扩展手段,进一步增强整体性能。当前,提升单代算力较为直接的方式是采用先进制程工艺。目前,这一方向仍将持续推进,例如从现有的7nm制程向5nm、4nm乃至3nm制程演进。然而,制程升级带来的性能提升红利正在逐步减弱,因此需要依靠系统协同来实现算力的有效突破。
此外,算力提升并非仅依赖于增加加速器的计算能力,更重要的是确保数据能够及时、高效地传输至加速器,从而提升整体系统效率,实现较高的帧率表现。这是单代芯片性能提升的关键所在。
算力的提升并非无限制的,其最终需满足车载部署的实际需求。鉴于当前车载散热系统中冷却液温度大多维持在65度左右,这对芯片能效提出了极高要求。在辅助驾驶芯片中,NPU的功耗最高,因此设计高效能的NPU成为关键。此外,通过采用近存计算技术及优化后端物理实现,亦可进一步降低功耗,从而实现算力的有效提升。
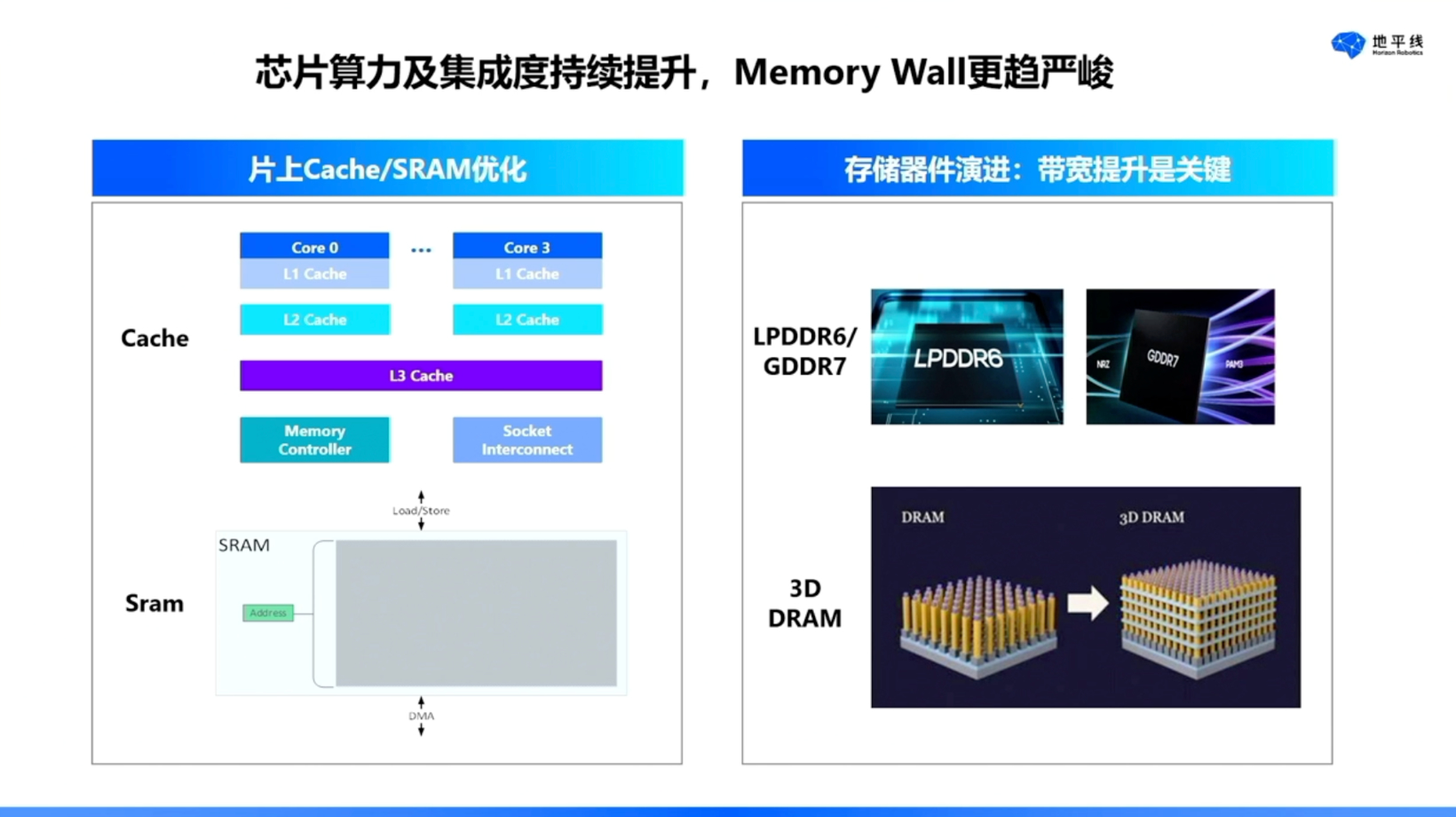
此外,还存在Memory Wall问题。随着算力提升以及集成度增高,这一问题将愈发严峻。针对此问题,我们的思考主要围绕两个维度展开。
一是关注片内的SRAM和Cache。算力提升需以数据有效传输为支撑,而片内的CPU Cache以及NPU SRAM等模块虽具备极高的数据传输速率,但容量相对有限。为解决这一问题,需依赖外部存储器如DDR,其特点在于容量较大,可满足当前大模型的存储需求。然而,DDR的速率与片上SRAM存在较大差距,因此提升外部存储带宽成为关键任务。
图源:演讲嘉宾素材
二是架构层面。当前市场上较为常见的架构是DSA,例如地平线的BPU以及华为的昇腾系列均属于此类架构。DSA架构的特点在于能效表现优异,但其设计主要面向特定领域,因此在通用性方面相较于通用GPU存在一定差距。为应对场景的多样性需求,当前DSA架构也在逐步融入通用性加速单元。例如,GPU厂商在面向深度学习领域时,开发了GPGPU结合Tensor Core的方案,该方案在通用性方面表现良好,但在能效和性能上仍不及DSA架构。
而,鉴于行业共同目标均是推进更高级别的辅助驾驶技术发展,为适应未来场景的多样性以及算法的通用性需求,通用计算架构与专用计算架构的融合将成为趋势。地平线现有的BPU基于DSA架构,但未来将向融合通用计算能力的方向演进。
后摩尔时代,单纯依靠工艺提升芯片性能的难度正日益增大。以业界情况来看,在更先进的A14、A16等制程上,厂商已转向通过DTCO方向来挖掘性能潜力。对于辅助驾驶芯片而言,同样需要采取类似策略,通过芯片底层定制标准单元、实现高性能物理设计,以及优化芯片架构中计算单元与总线的协同,从而将芯片性能发挥到极致。系统层面亦可借鉴此思路,集成更多加速模块。同时,在算法层面,推动算子与芯片的协同设计,开展更多定制化代码设计,以进一步提升性能。通过上述多维度的协同优化,不仅能够提升性能,还能在一定程度上降低能耗,进而减少散热与供电成本,实现系统整体优化。
在过去十年间,地平线在这一领域进行了诸多实践。2016年,地平线提出了“智能计算时代的新摩尔定律”。彼时,业界普遍认为芯片片上算力即代表实际算力,但时至今日,客户在评估芯片性能时,更倾向于通过实际测试板卡来验证,这反映出芯片实际性能的发挥不仅取决于芯片本身的计算能力,还涉及编译器优化、算法优化等多个层面。因此,唯有实现软硬件协同优化,才能充分释放芯片性能。
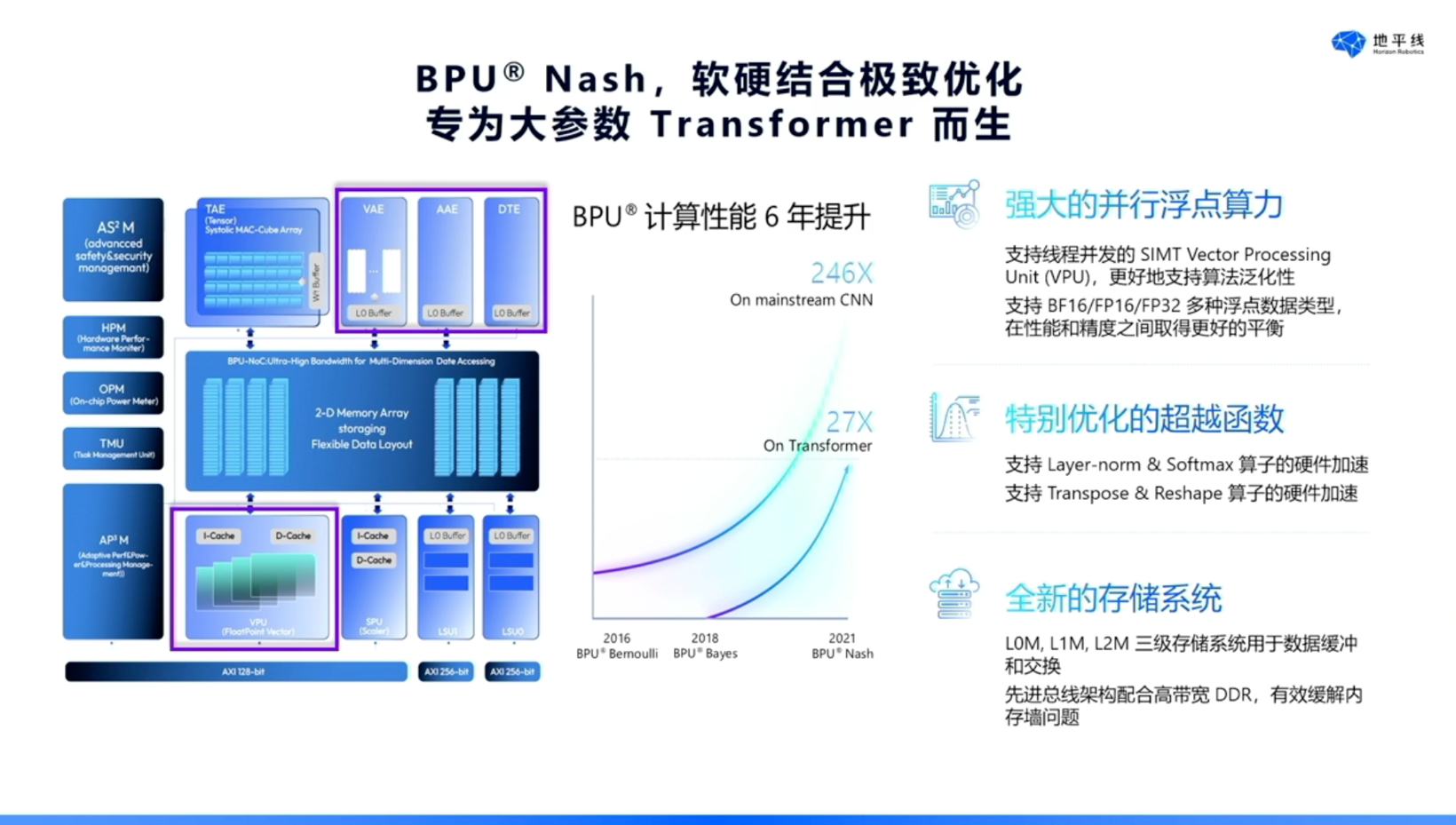
自2016年起,地平线的芯片架构历经三代演进,从初代的Bernoulli架构,到后续的Bayes架构,再到2021年推出的Nash架构。目前,地平线量产的征程6系列芯片即基于Nash架构打造。
关于Nash架构的特性,回顾BPU六年来的发展历程,其在CNN处理性能上实现了246倍的提升,在Transformer处理性能上则提升了27倍。此外,该架构新增了VPU,旨在增强芯片的通用性。同时,针对Transformer中常用的特定超越函数,我们采用了硬件固化设计,以此进一步提升Transformer的整体性能。在存储系统方面,Nash架构引入了全新的三级存储层次结构,通过协同总线与外部DDR存储器的优化配合,有效解决了Memory Wall问题。
图源:演讲嘉宾素材
随着J6B芯片近期完成回片测试,我们的征程6系列已实现全阶通关成熟,全面覆盖高、中、低三档市场。其中,中阶的征程6E与征程6M两款芯片已于去年年底实现量产,高阶和低阶的产品也将很快量产。征程6B也已牵手博世,将于2026年年中量产。
在高阶产品领域,地平线将持续突破创新,致力于为客户提供极致体验。而征程J6B芯片则聚焦于夯实基础性能,将安全性能作为核心标配,严格遵循安全第一的重要准则。
此外,征程J6P芯片的算力高达560 TOPS,配备18个A7八核处理器,内部CNN总线带宽达到1Tb/s,图像处理带宽性能达5.3Gpixel/s,同时内置MCU以帮助客户降低成本,其带宽超过200G。搭载征程6P的HSD城区辅助驾驶方案,将于Q3在奇瑞星纪元E05首发量产。
(以上内容来自地平线芯片产品总监沈建于2025年7月22日在第八届智能辅助驾驶大会发表的《软硬结合,打造智驾计算“芯”范式》主题演讲。)
(科技责编:拓荒牛








 晋ICP备17002471号-6
晋ICP备17002471号-6