极摩客EVO-X2 Mini AI工作站评测:AI Max+ 395加持顶级性能
这两年,AI 已经成为不止科技圈,而是各行各业都重点关注的焦点,AI 相关的产品与技术正以前所未有的速度渗透到人们工作、生活的方方面面,从事 AI 相关的开发者、极客也越来越多。面对新的时代和技术浪潮,只有以身入局,拥抱 AI,才能让技术真正为我们所用。
而如果恰好你就是一名 AI 初学者、初期开发者或者创业者,难免需要在本地搭建 AI 开发环境 ,进行 AI 开发、验证或者部署的开发性工作,这时候一台适合在本地完成这些工作的高性能主机就很重要了。
说到这,小编想到 AMD 在今年年初推出的代号“Strix Halo”的锐龙 AI Max 300 系列 APU,可以说就是专门为满足高端 AI PC 上述需求而量身打造的。

锐龙 AI Max 300 系列平台采用 Zen 5 CPU 和 RDNA 3.5 GPU 架构,并运用先进的芯粒(chiplets)封装技术。每个 Zen 5 CPU 核心位于独立的 CCD 上,两个 CCD 最高提供 16 颗 Zen 5 超大核心 32 线程,集成显卡(iGPU)最高拥有 40 个 RDNA 3.5 计算单元。
此外,该平台采用 LPDDR5x 内存标准,内存带宽高达 256GB/s,集成 50 TOPS“XDNA 2” NPU,为 Windows 11 AI+ PC 提供领先的 AI 性能。

目前市面上其实已经有不少搭载“Strix Halo”APU 的 AI PC 产品,刚好,最近IT之家拿到了其中一款来自极摩客的 EVO-X2 桌面 Mini AI 工作站,有着桌面 AI 超算中心之称(以下简称“极摩客 EVO-X2”),搭载系列顶级旗舰型号锐龙 AI Max+ 395,相信会很适合从事 AI 初学开发和极客们折腾 AI 使用。所以今天我们不妨对其进行一番测试,看看它的表现究竟如何。
一、外观设计
极摩客 EVO-X2 采用银白色的长方体包装盒,正面只有金色的“GMKtec”字样,看起来十分简洁利落。

打开包装极客看到极摩客 EVO-X2 桌面 AI 超算中心主机本体,这款主机为德国红点奖设计师亲自操刀设计,表面采用国标“1050”再生铝材质,带来更高品质的机身质感。

极摩客 EVO-X2 整体采用两个大小不一的扁平长方体重叠构成的视觉三明治设计,银色的再生铝金属盖板半包围式覆盖机身的顶部、底部和一个侧面。机身顶部平面的左下角还做了削边的设计,让整机看起来更有设计感和极客感。

银色的金属盖板只是外壳,中间的黑色部分才是真正意义上的主机本体,包含了主板、接口和散热模组等组件。

除了上方的三角形氛围灯开关,所有的接口和按键都在侧面的黑色区域内,包括绿色醒目的电源键、Performance 性能模式切换键、SD 卡插槽、1 个 USB 4 Type-C 接口,2 个 USB 3.2 Type-A 接口,1 个 3.5mm 音频接口。

背面则提供了 1 个电源插孔、1 个 3.5mm 音频接口、1 个 Giga LAN (RJ45) 网口、1 个 USB3.2
(Gen2) 接口、1 个 USB4 Type-C 接口、1 个 DP 1.4 接口,1 个 HDMI 2.1 接口和 2 个 USB 2.0 接口。


极摩客 EVO-X2 作为一款桌面 AI Mini 工作站主机,整体还是十分小巧紧凑的,IT之家实测机身的厚度为 77.0mm,长和宽分别为 23.2cm 和 22.1cm。


机身重量方面,小编实测为 1666g,基本上和一台普通的超轻薄本差不多重,放在背包里不会觉得很坠重。

配件方面,极摩客 EVO-X2 随机附赠了电源线和一根 HDMI 线,此外还有说明书和保修卡,都是常规配件。

整体来说,极摩客 EVO-X2 小巧精致,有设计感,放在桌面上可以起到很好的颜值点缀作用,同时也比较便携,对于可能需要移动办公和开发的用户来说还是比较友好的。

二、性能概述
正如前文所说,性能上,极摩客 EVO-X2 最大的看点自然是搭载了 AMD“Strix Halo”系列旗舰芯片锐龙 AI Max+ 395,这款 APU 拥有 Zen 5 架构 CPU,16 超大核心 32 线程设计,最高频率可达 5.1 GHz,并配备了 80MB 的缓存,整体规格非常强悍。
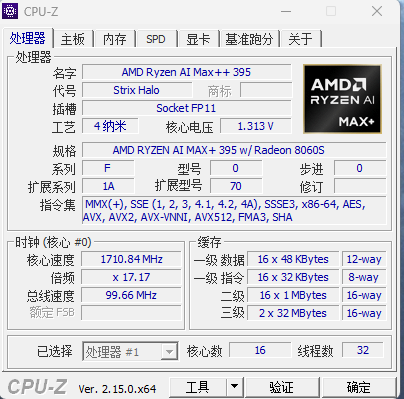
同时它还集成了 Radeon 8060S 显卡。拥有 40 个 RDNA 3.5 架构计算单元,cTDP 范围在 45-120W 之间,可以平替 RTX 4070 独显,能在 1080p 分辦率下流畅运行各种游戏,还可驱动四台超高清 8K UHD 显示器,并能高效编码和解码多种视频 codec,如 AVC、HEVC、VP9 和 AV1。
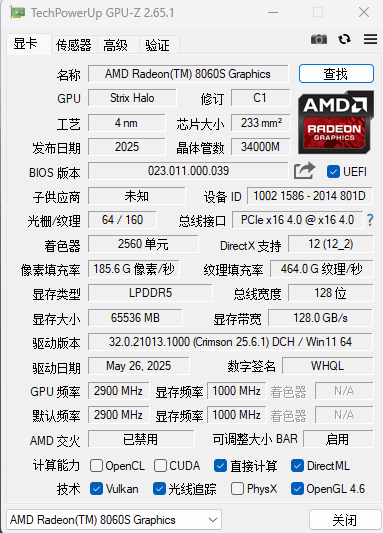
它的 NPU 采用了全新的 XDNA 2 架构,Al 算力 50 TOPS,总性能高达 126 TOPS。根据 AMD 的介绍,其在 Windows 11 Al+PC 中,GPU 在 LM Studio 里的 Al 性能比 NVIDIA GeForce RTX 4090 高出 2.2 倍,且功耗降低 87%。

然后是在内存和存储方面,极摩客 X2 采用 128GB (16GB*8) LPDDR5X 8000MHz 低功耗内存,不可拆卸,同时还有 2TB PCle 4.0SSD,双 M.2 高速固态插槽,最大支持 8TB。
上手之后,IT之家也对极摩客 X2 做了一些简单的基准性能测试,好让大家整体了解这款迷你主机的性能。
首先是 CPU 的性能测试,在《CineBench R23》中,锐龙 AI Max+ 395 取得了单核 1993 pts,多核 36612 pts 的表现,性能十分顶级。
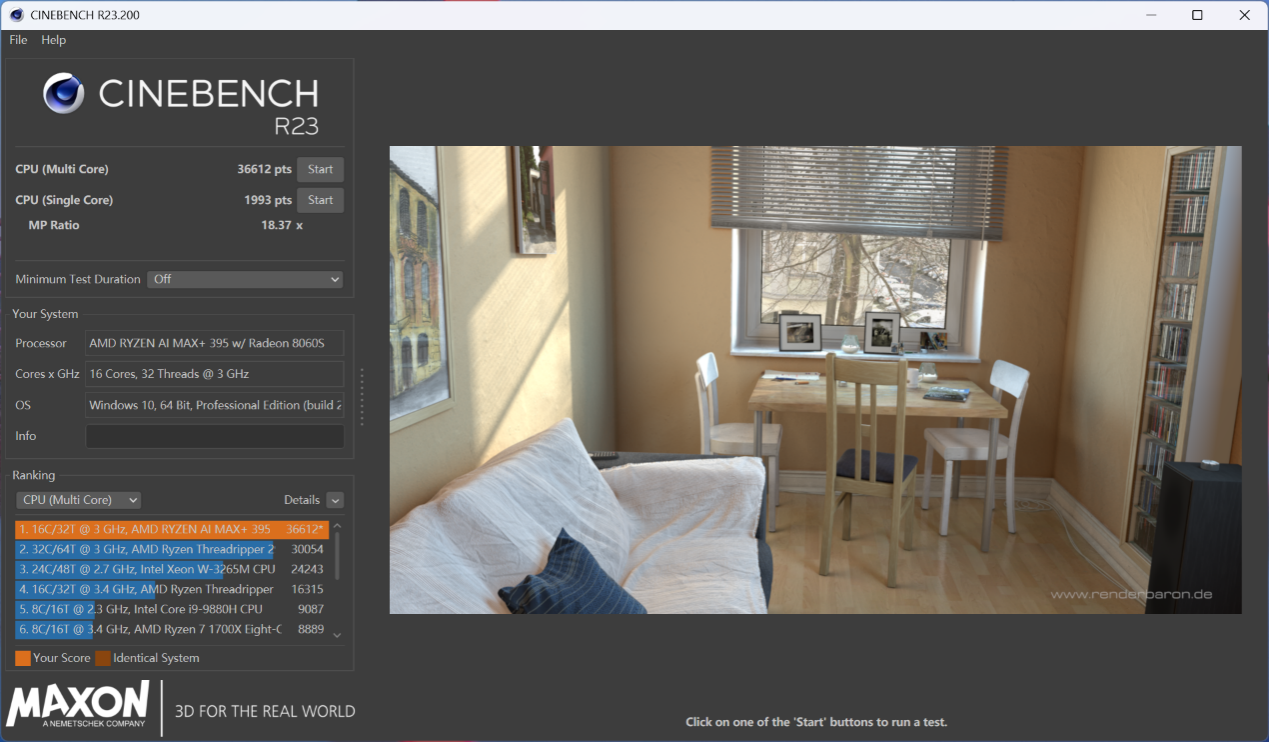
CineBench 2024 中,锐龙 AI Max+ 395 单核为 113 pts,多核为 1739 pts。

GPU 方面,IT之家测了《3D Mark》的 Time Spy 项目,得到显卡成绩为 10870 分,综合得分 10698 分。
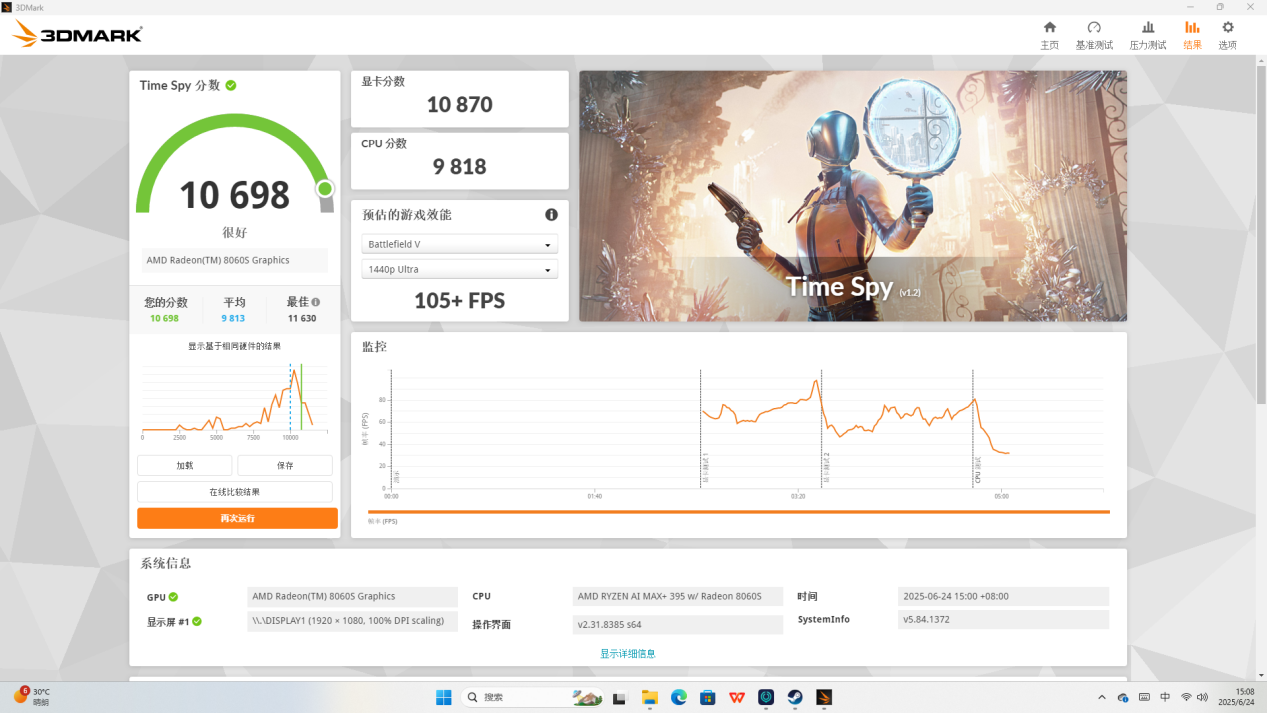
在 Fire Strike 项目中,锐龙 AI Max+ 395 显卡成绩为 28286 分,综合得分达到 24614 分。
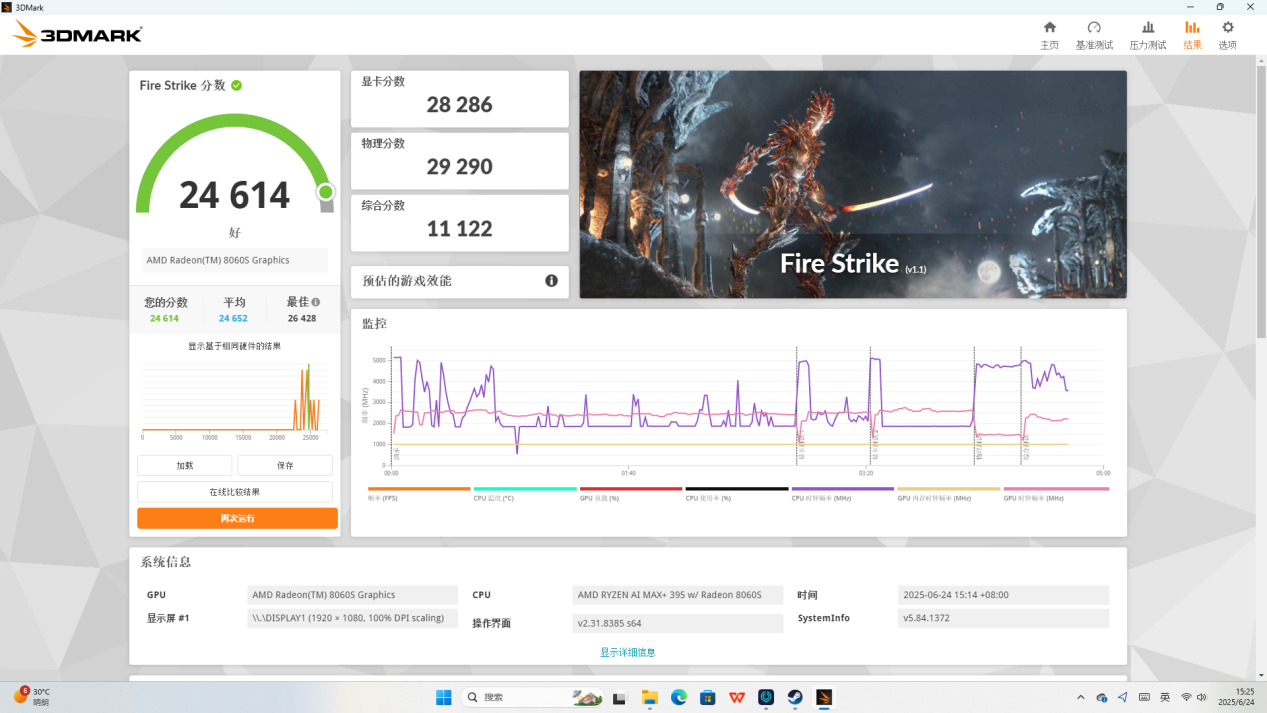
然后是 Solar Bay 项目的测试,锐龙 AI Max+ 395 显卡跑到 185.99 FPS,综合得分 48915 分。
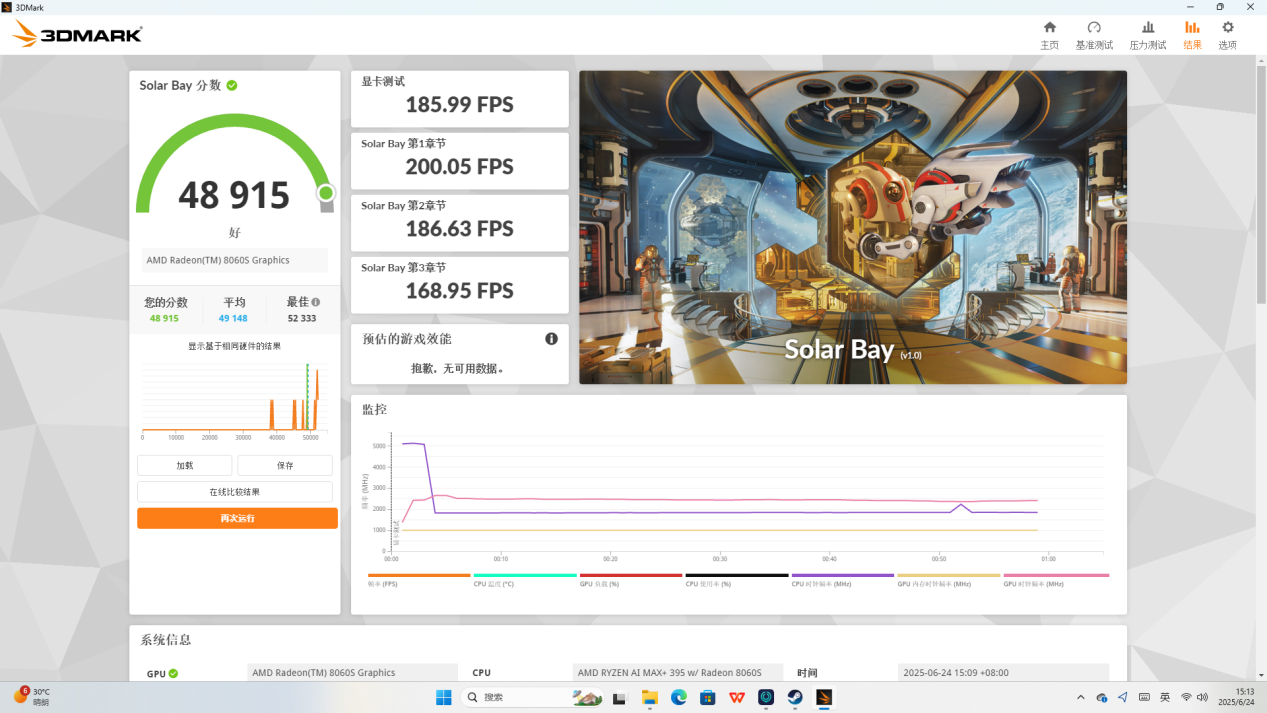
可以看到,无论 CPU 还是 GPU,锐龙 AI Max+ 395 的性能都非常亮眼,足以和目前中高端的游戏本相抗衡了。
还有内存方面小编也做了测试,通过 AIDA 64 的内存测试工具测得读取速度达到 119.47 GB/s,写入速度达到 211.96 GB/s,拷贝速度为 156.61 GB/s,时延为 139.8 ns。
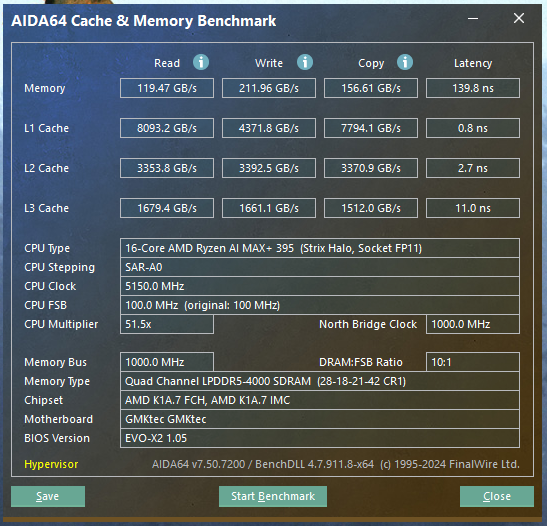
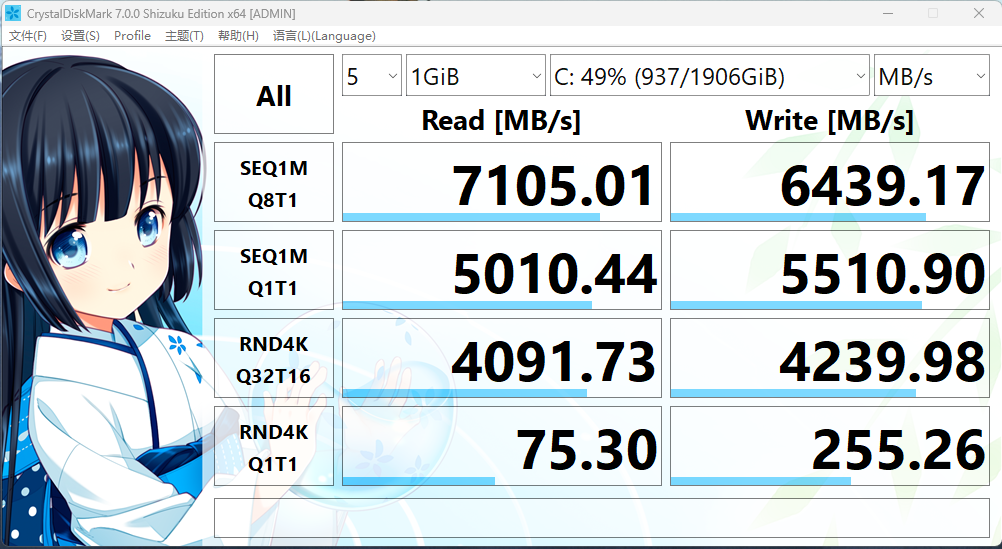
接着小编还使用 CrystalDiskMark 测了 SSD 的读写性能,在 SEQ1M Q8T1 项目中,这块 SSD 的读取速度为 7105.01 MB/s,写入速度为 6439.17 MB/s。
三、AI 功能体验
我们知道,AMD 锐龙 AI Max+ 395 拥有为大模型量身打造的超强算力,这让以往不能在本地部署的超大模型(例如文生文的 70B,32B 大模型,文生图的 flux 模型等)都可以在搭载锐龙 AI Max+ 395 的极摩客 EVO-X2 中顺利运行,对于 AI 初学者、初级开发者来说无疑会非常友好。所以接下来IT之家也将重点为大家体验使用极摩客 EVO-X2 在本地部署各类 AI 模型以及相关的应用体验。
1、超大模型本地部署体验
首先我们尝试用极摩客 EVO-X2 在本地运行超大参数的模型,看看它能否流畅、顺利地应对。这里我们先以拥有 235B 参数的 Qwen3-235B-A22B-IQ2_S 模型为例,这个参数量的模型在本地运行对于性能的开销是非常大的,而这里我们使用的是 AMD AI 生态伙伴模优优科技优化的模型文件,利用锐龙 AI Max+ 395 统一内存设计和高达 96GB 容量分配给显存,通过定制化的内存调度策略和深度量化优化,从而让全尺寸 Qwen3-235B 模型能够在 AI PC 上流畅运行。
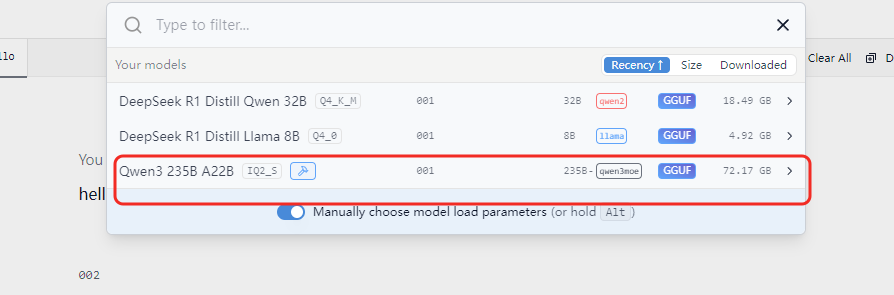
具体来说,使用时我们用 LM Studio 加载该模型,然后开启对话,首先提问大模型一个类似人情世故的问题:两个人正常交谈,其中一个男人夸赞对方做事能力强,对方回答 " 哪里,哪里”,请问这里的“哪里,哪里”是什么意思?”

面对这样超大参数的模型,可以看到,在处理这个问题的过程中,AMD 锐龙 AI Max+ 395 的 GPU 的负载达到 49%,CPU 负载达到 61%,内存负载达到 60%。
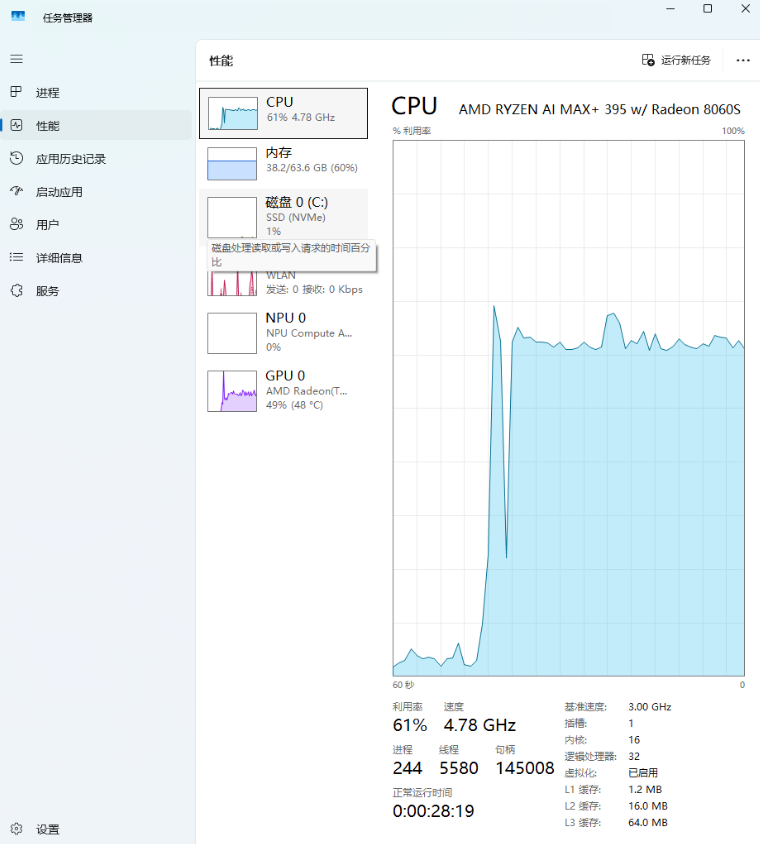
而此时,机器工作时的噪音仅为 47.8dBA,并不算高。

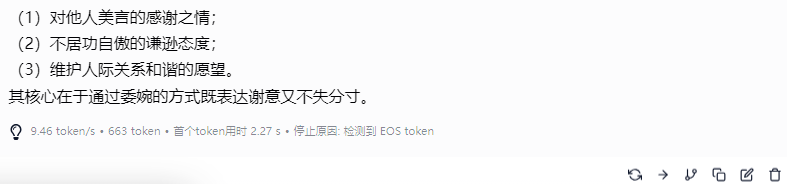
经过思考和推理后,大模型做出了回答,整个回答的内容非常严谨,一共输出了 663tokens,速度为 9.46 tokens / s,首个 token 输出时延为 2.27s。
接下来,小编让大模型用莎士比亚的风格写一首关于人工智能的十四行诗,包含隐喻和押韵,并解释韵律格式。
经过 32.84 秒的推理和思考后,大模型写了一首英文诗。同时也解释了韵律格式和实用的手法。

回答一共输出 886 个 tokens,速度为 9.06 tokens / s,首个 token 输出的时延仅为 0.11s。

然后,小编又给了它一个鸡兔同笼的数学题,可以看到这次大模型花了 2 分钟 52 秒的时间来思考和推理,随后给出了不同的解答方法,最后结果都是正确的。

这次一共输出 1482tokens,速度为 8.72 tokens / s,首个 token 输出的时延为 2.22s。

接下来,小编换了另一个超大参数量的大模型:DeepSeek-V3。这和我们刚才测试的 Qwen3-235B-A22B-IQ2_S 几乎是同量级的模型,全量部署在极摩客 EVO-X2,话不多说,我们接着看它的表现。
在测试中,小编先让它帮我写一份公司周末举办的产品说明会活动策划,DeepSeek 直接给出了回答,整体内容清晰明了,符合小编提出的要求。

本次回答一共输出 1105 tokens,速度为 4.39 tokens / s,首个 token 输出的时延为 5.47s,速度有点慢,但胜在可以稳定运行。

然后还是用一道数学题来考验大模型,常见的距离问题,DeepSeek 给出的解法描述上有点复杂,不过最终的答案是正确的。

这次回答输出了 874 tokens,速度为 4.55 tokens / s,首个 token 输出时延为 5.75s。

最后,小编让它帮我写一篇去北京的五天四夜游玩攻略,DeepSeek 直接出了一份简单的攻略,不过整体内容上没什么毛病。

本次回答一共输出 473 tokens,速度为 3.51 tokens / s,首个 token 输出的时延为 2.93s。

可以看到,在 AMD 锐龙 AI Max+ 395 的加持下,用极摩客 EVO-X2 在本地部署 Qwen3-235B 和 DeepSeek-V3 这样的超大参数模型,依然能获得十分流畅的体验,和大模型交流几乎不需要过多等待,tokens 输出的速度也是比较快的。这样的体验放在半年多前的桌面 mini 主机上或者其他轻薄 AI PC 上几乎是不敢想的。
2、Amuse + 本地模型的创意内容生成体验
做完了本地部署超大参数模型的体验,下面我们来看看文生图、文生视频这样的创意内容生成方向,极摩客 EVO-X2 能带来怎样的体验。
具体操作上,小编使用 Amuse 3.0 这款 UI 软件来加载本地的模型。作为 AMD 的合作伙伴,Amuse 一直以来对 AMD 平台的 AI 性能表现是有着深度优化的,因此也是我们评测中的常客了。并且 Amuse 还支持 AMD XDNA Super Resolution 功能,可以在文生图时利用 AMD 平台 NPU 的能力对生成的图片进行超分到 2 倍的分辨率。
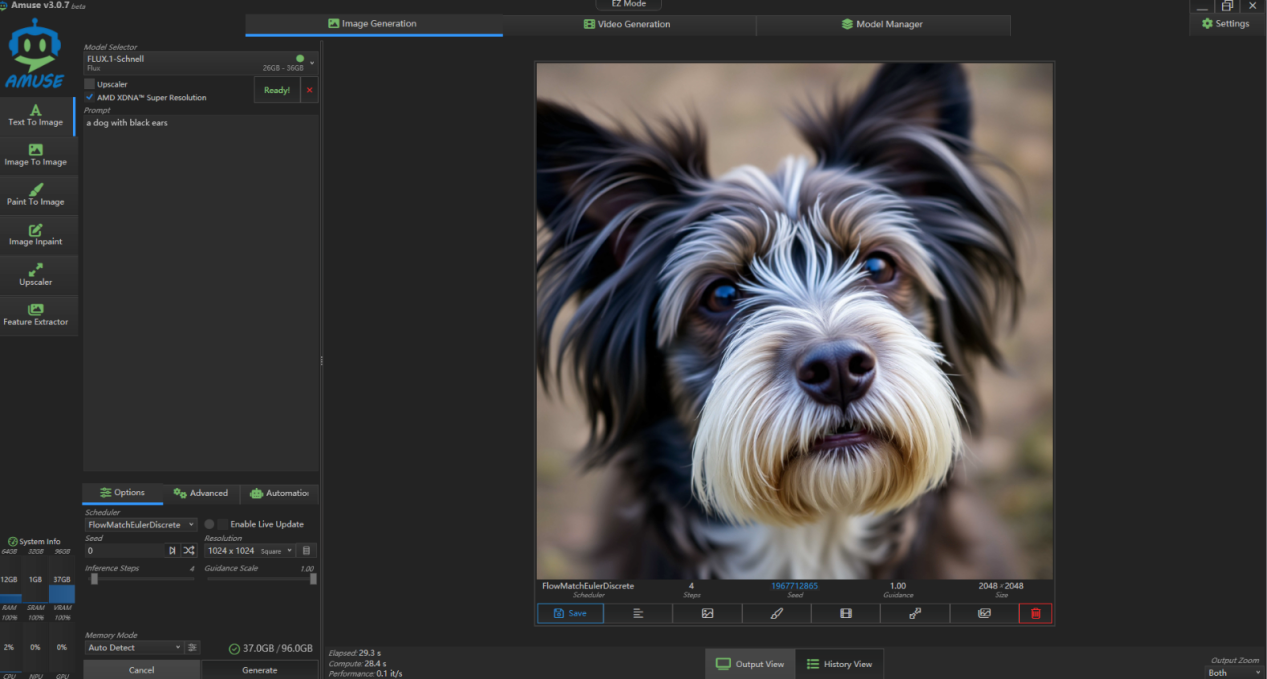
在测试时,小编首先使用 26GB 大小的 Flux-schnell 模型来进行文生图,先让它生成一张“一只黑色耳朵的狗”的图片,迭代步数为 4 步,分辨率为 1024×1024,输出时超分到 2048×2048。
在生成过程中,锐龙 AI Max+ 395 处理器 GPU 频繁冲高到 100%,CPU 占用为 4%,内存占用为 20% 左右。
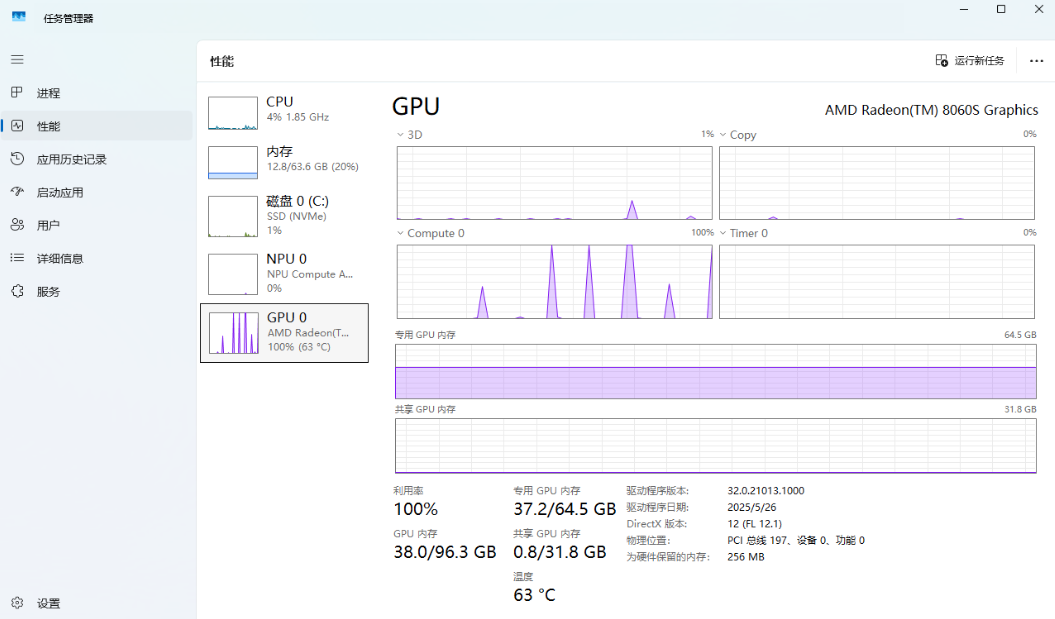
可以看到,本次生图耗时 29.3s,性能为 0.1it/s。
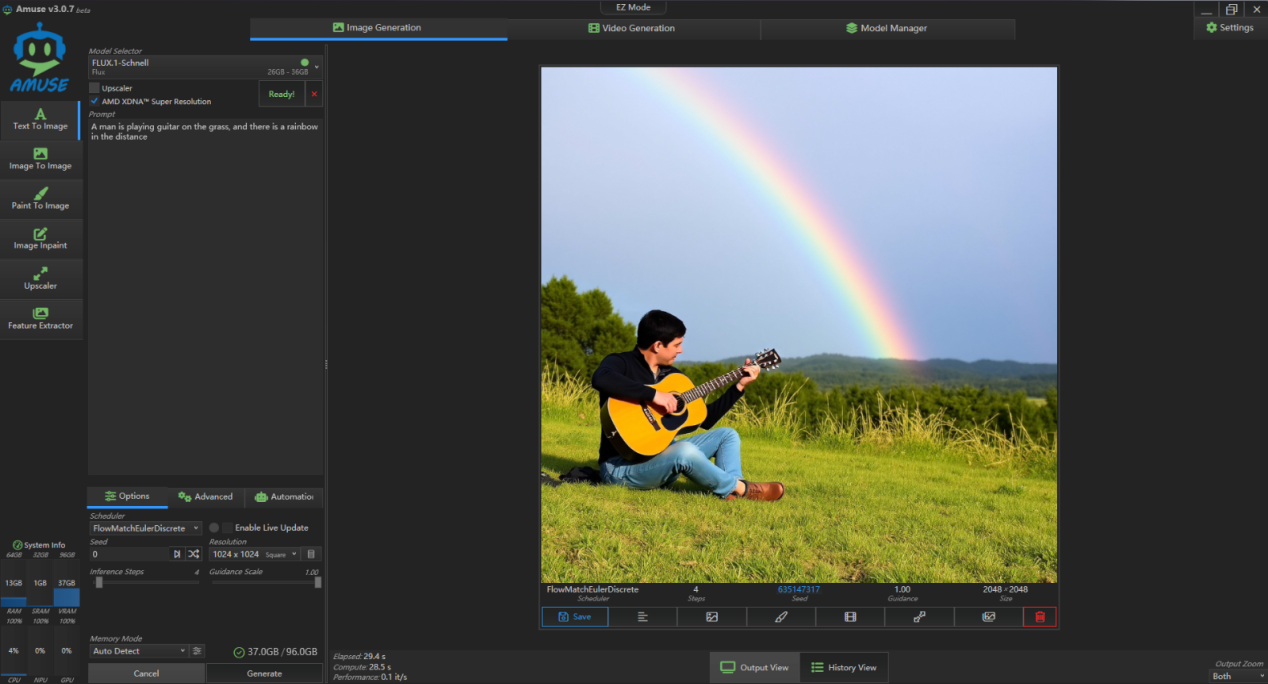
然后,小编提高一下复杂程度,让它生成一张主题为“一个男人在草地上弹吉他,天空中出现一道彩虹”,可以看到生成的照片很自然,就像真实的照片一样。而生成这张图耗时为 29.4s。性能表现为 0.1 it/s。
接着小编又测试了文生视频的能力,使用大小为 6GB 的 Locomotion 模型,视频分辨率为 512×512,视频时长为 8s。测试时,小编输入提示词“一只小船在平静的湖面上漂荡”,从结果上看 Locomotion 生成的视频“AI 味”还是挺重的,视频画面也有不自然之处,但整体还是不错的。
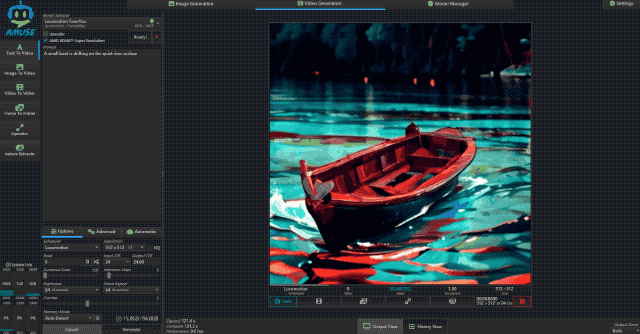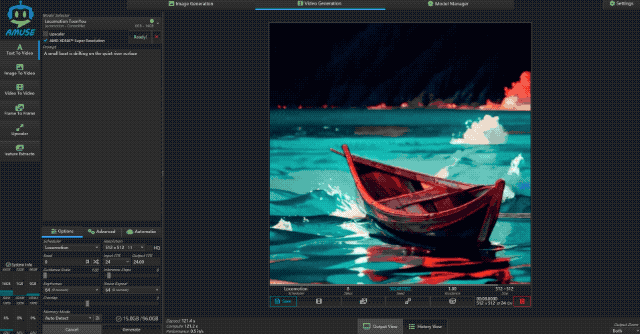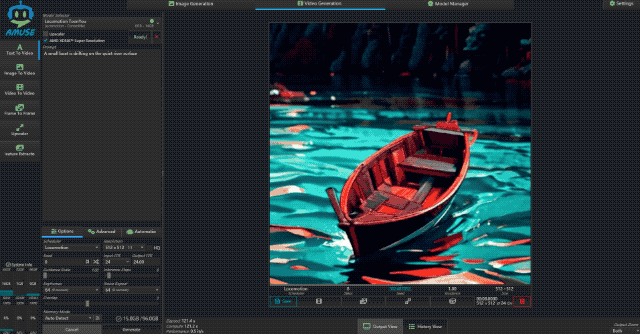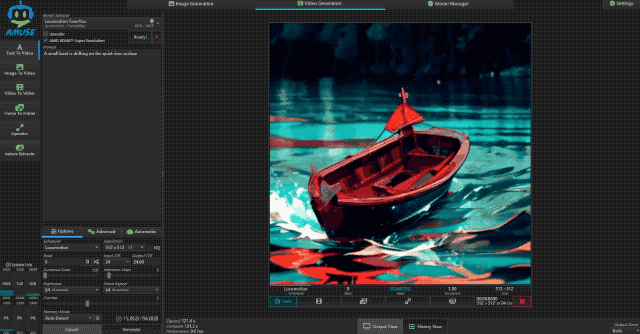
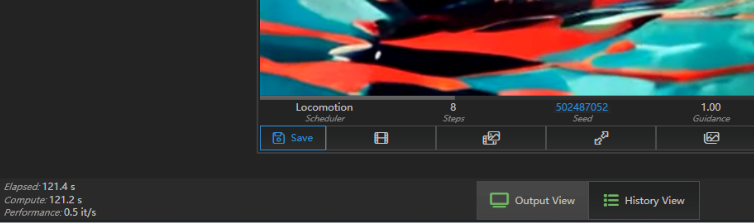
生成这样一段 8 秒的视频,极摩客 EVO-X2 耗时为 121.4s,速度为 0.5 it/s,还是挺快的。
接着小编又让它生成一段主题为“一边走路一边打电话的男人”的视频,这次的时长设为 10s,可以看到输出的视频风格有点诡异,不过依然符合主题。
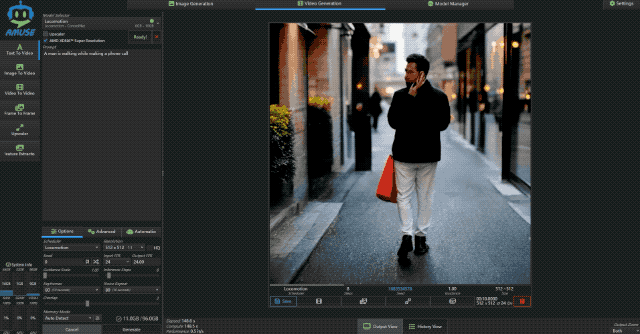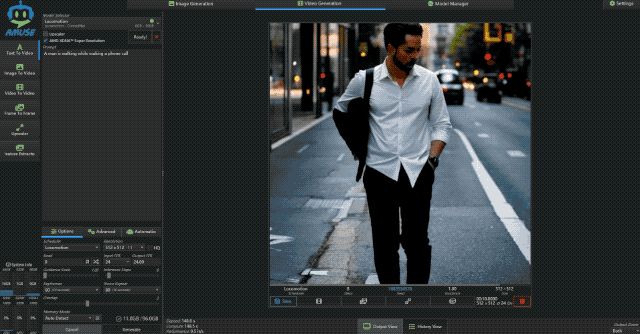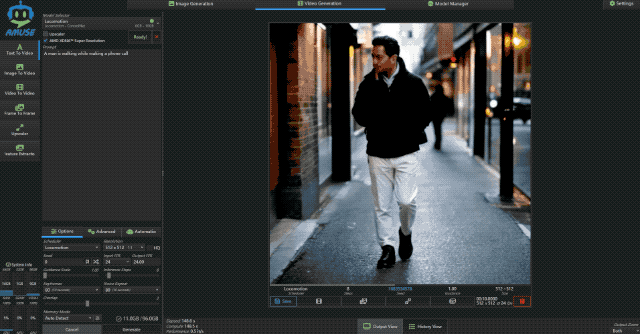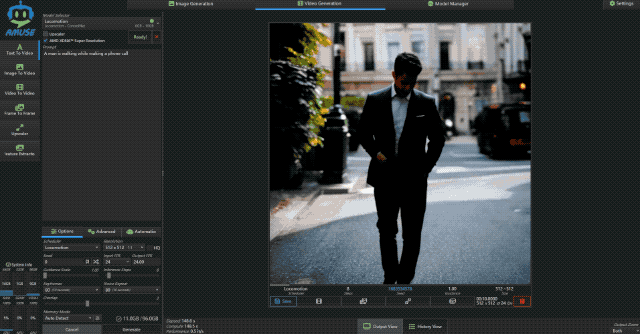
而生成这样一个 512×512 的 10s 视频,极摩客 EVO-X2 耗时仅为 148.6s,性能为 0.5 it/s,这个表现已经是超出预期了。
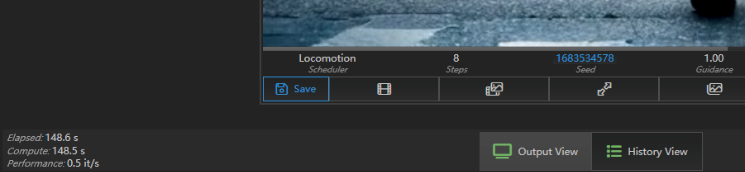
可以看到,使用极摩客 EVO-X2 在本地部署 Flux-schnell、Locomotion 这样的大型图像、视频生成模型也是可行的,而且使用体验也很流畅,生成 2048×2048 这样的高分辨率模型也只需 25 秒左右的时间,这对于从事创意工作的用户来说,无疑是多了一个可以随时随地使用、不受网络限制的辅助创作工具。
3、MCP 本地部署体验
接下来,IT之家又尝试了在极摩客 EVO-X2 上本地部署 MCP Agent 的体验。MCP(Model Context Protocol)又叫大模型上下文协议,它为大模型提供了一个“万能插座”式的接口,使得 AI 应用能够安全地访问和操作本地及远程数据。在日常工作和学习中,我们经常需要与浏览器、文件、数据库和代码仓库等外部工具进行交互。在传统方式中,我们需要手动截图或复制文本,再将其粘贴到 AI 窗口中进行对话,MCP 服务却充当 AI 和外部工具之间的桥梁,能够自动替代人类访问和操作这些外部工具。
具体测试时,小编在电脑端用本地 LM Studio+Cherry Studio 的形式来进行,首先我们在 LM Studio 中部署本地大模型,这里小编部署的是 Qwen3-8B-Q4_K_M 8B 大模型,大小为 5.03 GB,然后用 Cherry Studio 配置 MCP Server,然后在 Cherry Studio 里面进行和 MCP 的交互。
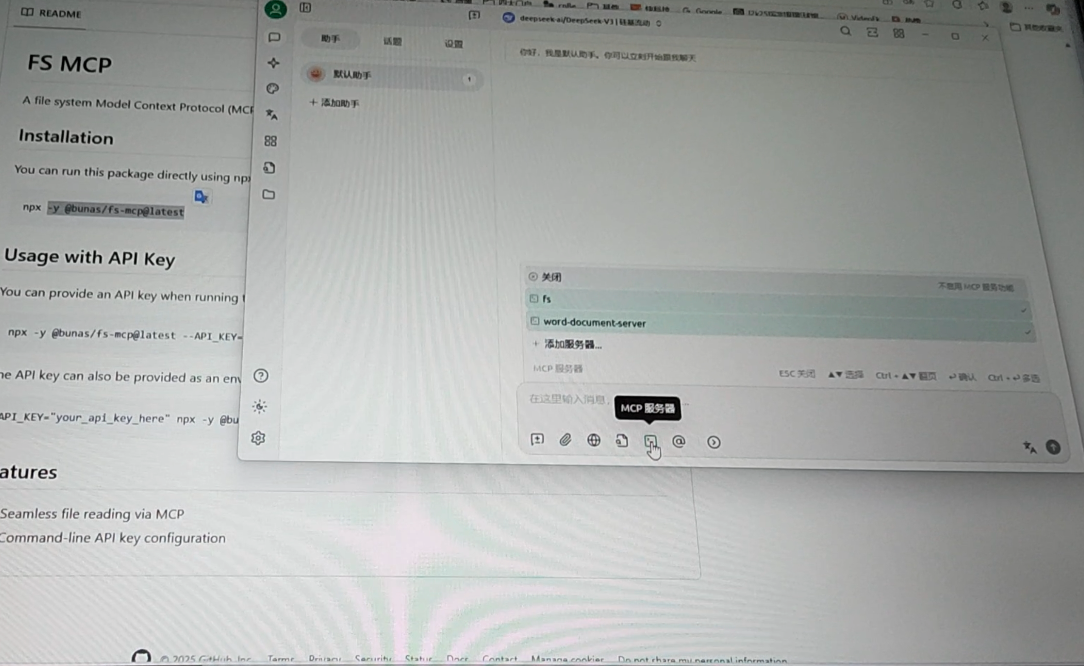
这里以让它以“信心”为主题写一个 300 字左右的短篇小说,展示给我后,保存小说内容到 C:\Users\ithome\Desktop\output\ 信心.docx 这个指定的本地目录中。
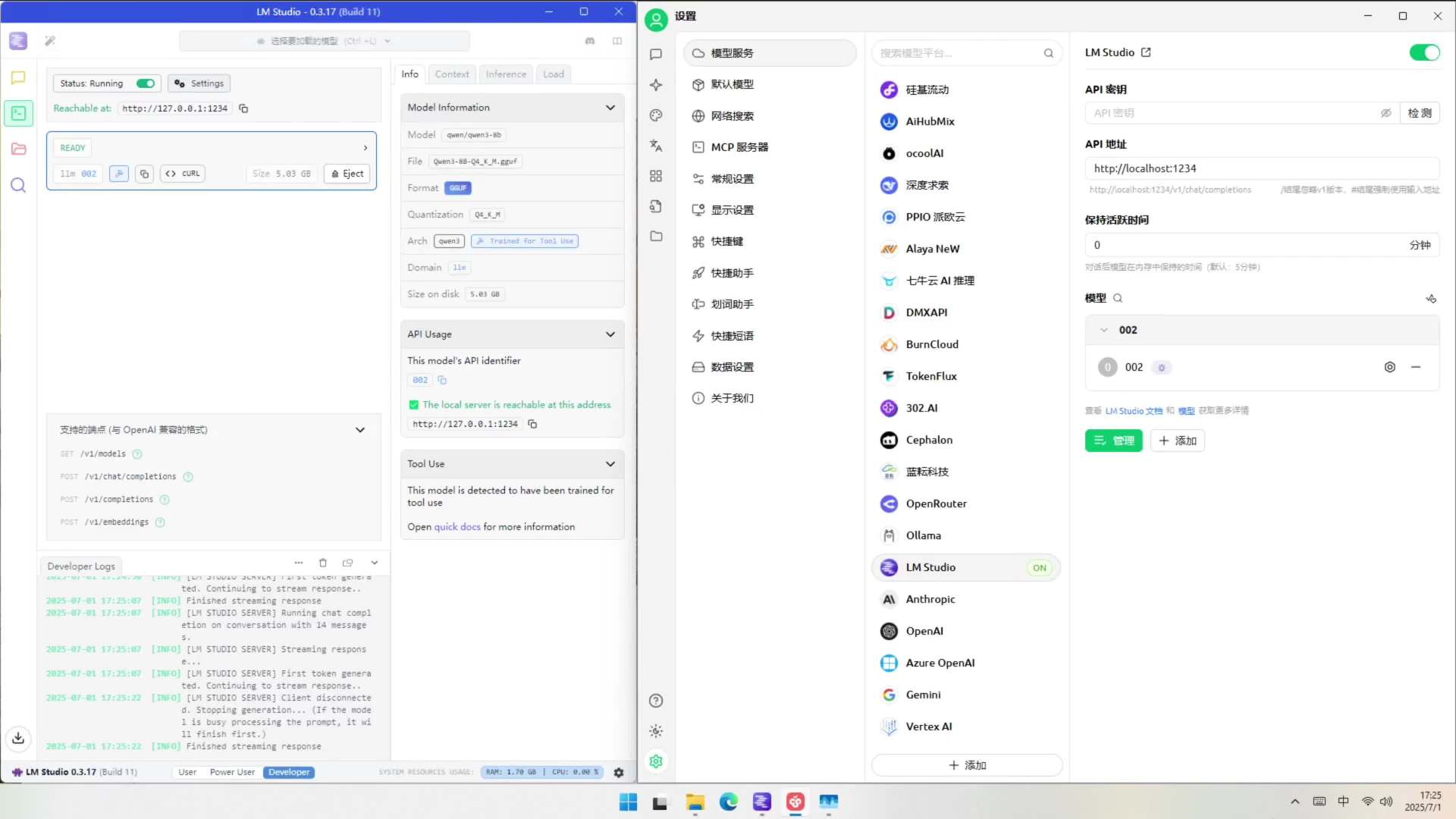
可以看到,在极摩客 EVO-X2 上完成这个操作还是很丝滑的,大模型也成功在本地创建了名为“信心”的小说文档,打开后可以看到里面的内容和模型生成时的文字内容是一样的。
而在 MCP 服务运行过程中,Radeon 8060S 集成显卡的占用基本上维持在 94% 以上,内存占用达到 24% 左右,CPU 占用达到 8%。
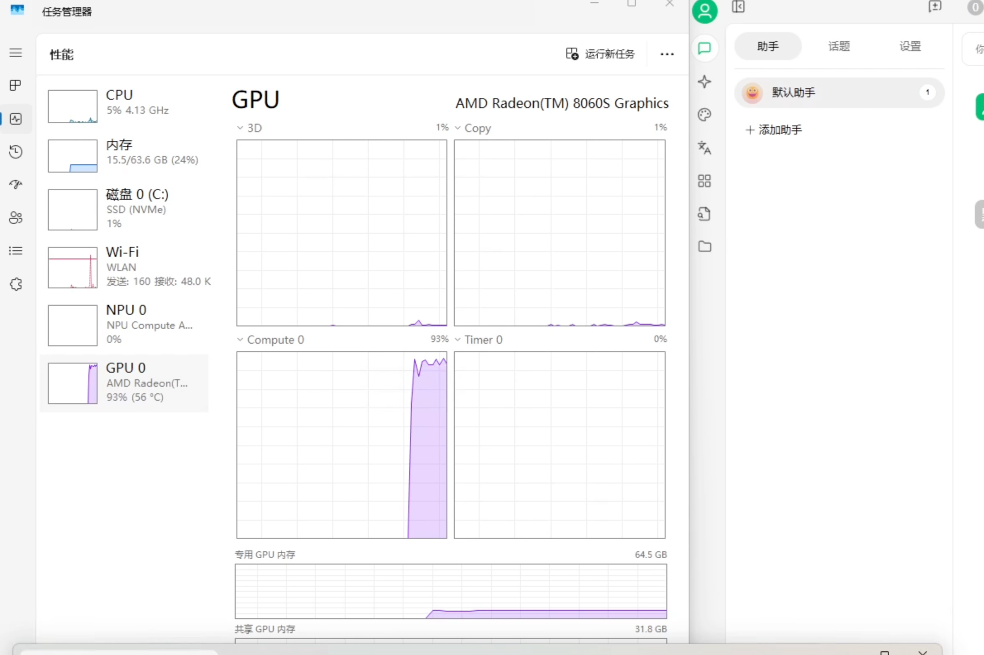
此时极摩客 EVO-X2 绝对算是高负载运行了,但运行时的噪音依然不大,噪音还是 47dBA 左右,完全不扰人。

四、结语
总体来说,可以看到极摩客 EVO-X2 桌面 Mini AI 工作站主机凭借 AMD 锐龙 AI Max+ 395 APU 的强劲性能,为 AI 开发者与极客带来了可以说是颠覆性的本地开发体验。
其搭载的锐龙 AI Max+ 395 芯片,以 50 TOPS 算力的 XDNA 2 架构 NPU 与高达 96GB 可分配显存的统一内存设计,彻底打破了“超大模型无法本地部署”的技术壁垒 —— 无论是 235B 参数的 Qwen3 模型,还是 236B 的 DeepSeek-IQ2_M,都能在极摩客 EVO-X2 中流畅运行,让开发者彻底告别云端部署的网络延迟与 token 计费焦虑。设备使用成本大幅降低,算法和模型数据还不容易外泄,让用户隐私、算法和数据模型更加安全。

得益于 Radeon 8060S 集成显卡与 LPDDR5X 8000MHz 内存的协同,主机不仅能轻松加载单个超大模型,更支持多模型并行运行,配合 Windows 11 系统的深度优化,实现了对 LM Studio、Amuse 3.0 等主流 AI 工具的无缝兼容。从本地部署 Qwen3 大模型进行自然语言交互,到通过 Amuse + 调用 Flux-schnell 模型生成 2048×2048 分辨率图像,再到利用 MCP 协议打通本地工具链,极摩客 EVO-X2 以“无网络依赖、低延迟响应、高算力释放”的特性,构建起覆盖开发、验证及部署全流程的本地 AI 生态。
对于 AI 初学者与创业者而言,这台主机不仅是性能强劲的开发平台,更是降低技术门槛的“入场券”—— 无需依赖云端服务,即可在本地完成大模型训练、创意内容生成与工具链集成,让 AI 技术真正从理论走向实践。
同时值得一提的是,除了这款极摩客 EVO-X2,近期其他搭载锐龙 AI Max+ 395 处理器的桌面 Mini AI 工作站、移动工作站产品也都已经陆续上市,比如 ROG 幻 X 2025、惠普(HP)战 99 Ultra 高性能笔记本移动工作站等等,如果你对 AI 感兴趣,希望深入挖掘 AI PC 本地应用的潜力,那么不妨尝试一下。
(科技责编:拓荒牛








 晋ICP备17002471号-6
晋ICP备17002471号-6