DeepSeek-V3.1 正式发布,官方详解迈向 AI Agent 时代的第一步
IT之家 8 月 21 日消息,深度求索官方今日正式对外发布 DeepSeek-V3.1。本次升级包含以下主要变化:
- 混合推理架构:一个模型同时支持思考模式与非思考模式;
- 更高的思考效率:相比 DeepSeek-R1-0528,DeepSeek-V3.1-Think 能在更短时间内给出答案;
- 更强的 Agent 能力:通过 Post-Training 优化,新模型在工具使用与智能体任务中的表现有较大提升。
官方 App 与网页端模型已同步升级为 DeepSeek-V3.1。用户可以通过“深度思考”按钮,实现思考模式与非思考模式的自由切换。
DeepSeek API 也已同步升级,deepseek-chat 对应非思考模式,deepseek-reasoner 对应思考模式,且上下文均已扩展为 128K。同时,API Beta 接口支持了 strict 模式的 Function Calling,以确保输出的 Function 满足 schema 定义。
另外,深度求索增加了对 Anthropic API 格式的支持,让用户可以将 DeepSeek-V3.1 的能力接入 Claude Code 框架。
工具调用 / 智能体支持增强
编程智能体
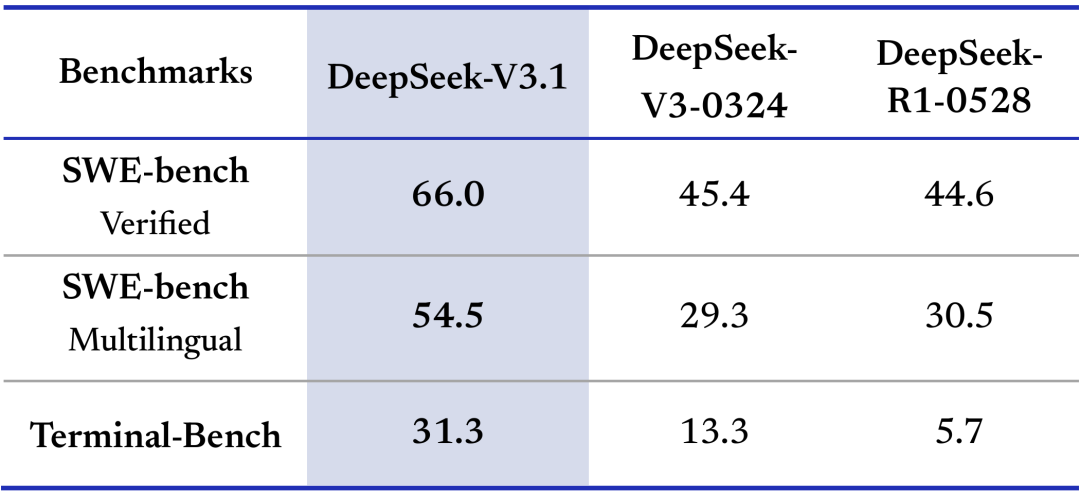
在代码修复测评 SWE 与命令行终端环境下的复杂任务(Terminal-Bench)测试中,DeepSeek-V3.1 相比之前的 DeepSeek 系列模型有明显提高。
搜索智能体
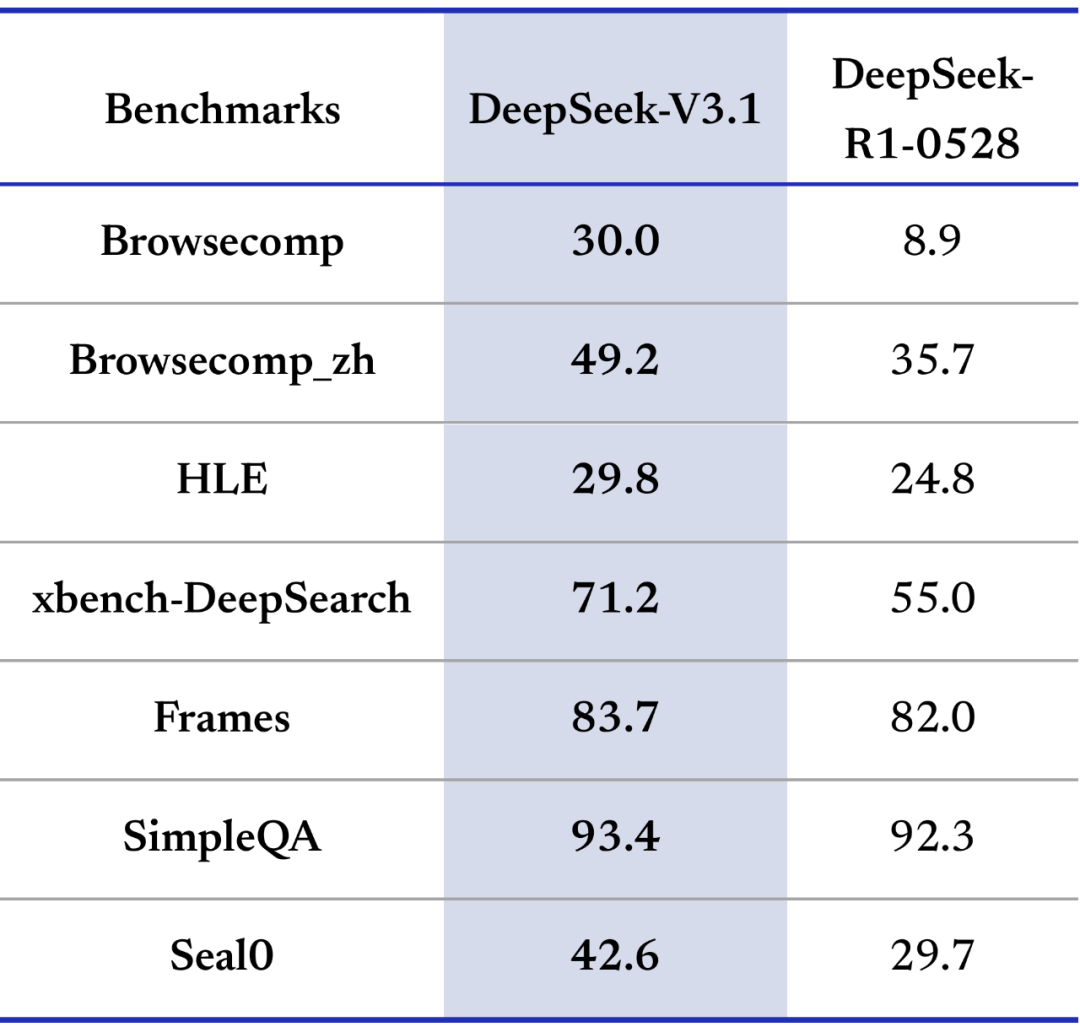
DeepSeek-V3.1 在多项搜索评测指标上取得了较大提升。在需要多步推理的复杂搜索测试(browsecomp)与多学科专家级难题测试(HLE)上,DeepSeek-V3.1 性能已大幅领先 R1-0528。
思考效率提升
深度求索官方的测试结果显示,经过思维链压缩训练后,V3.1-Think 在输出 token 数减少 20%-50% 的情况下,各项任务的平均表现与 R1-0528 持平。
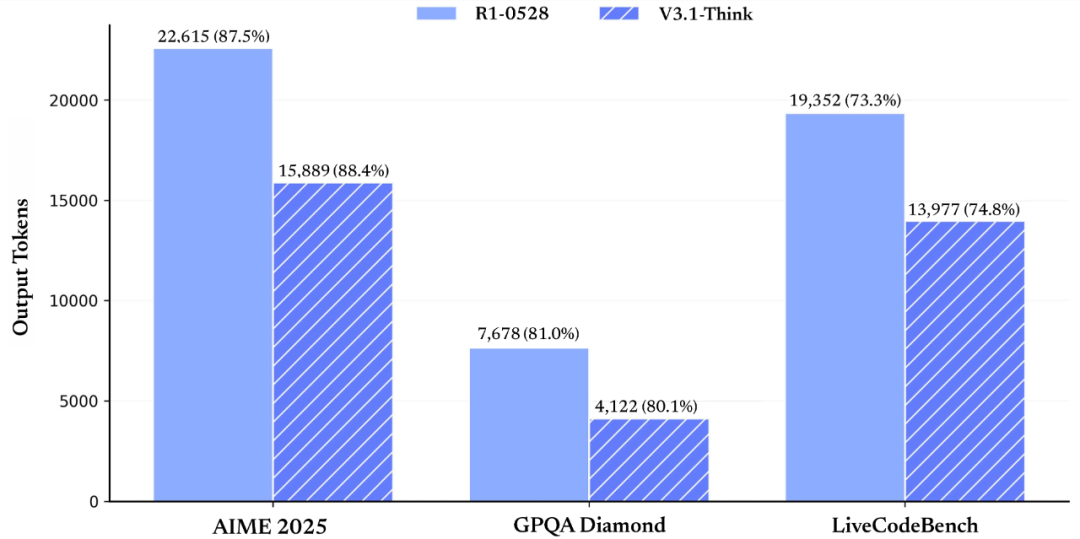
同时,V3.1 在非思考模式下的输出长度也得到了有效控制,相比于 DeepSeek-V3-0324 ,能够在输出长度明显减少的情况下保持相同的模型性能。
API & 模型开源
模型开源
V3.1 的 Base 模型在 V3 的基础上重新做了外扩训练,一共增加训练了 840B tokens。Base 模型与后训练模型均已在 Huggingface 与魔搭开源。IT之家附开源地址:
Base 模型:
- Hugging Face:
- 魔搭:
后训练模型:
- Hugging Face:
- 魔搭:
需要注意的是,DeepSeek-V3.1 使用了 UE8M0 FP8 Scale 的参数精度。另外,V3.1 对分词器及 chat template 进行了较大调整,与 DeepSeek-V3 存在明显差异。建议有部署需求的用户仔细阅读新版说明文档。
价格调整
深度求索将于北京时间 2025 年 9 月 6 日凌晨起,对 DeepSeek 开放平台 API 接口调用价格进行如下调整:
- 执行新版价格表(如下图所示,详见定价页面);
- 取消夜间时段优惠。

在 9 月 6 日前,所有 API 服务仍按原价格政策计费,用户可继续享受当前优惠。同时,为更好地满足用户的调用需求,深度求索已进一步扩容 API 服务资源。
(资讯责编:拓荒牛















 晋ICP备17002471号-6
晋ICP备17002471号-6